About the Author

Arjen Lentz is a former Community Relations Manager at MySQL. He is currently the owner of Open Query and lives in Brisbane, Australia.

MySQL Storage Engine Architecture, Part 2: An In-Depth Look
MySQL Storage Engine Architecture, Part 2: An In-Depth Look
In Part Two of this article we will take a more in-depth look at the features of the different storage engines that are available in MySQL Server and MySQL Cluster.
MyISAM
MyISAM has been the default storage engine since version 3.23. With MyISAM, each database is a directory, with each table stored in a separate set of files.

For an individual table, the .frm file contains information
about the table structure — effectively, an internal representation of
the CREATE TABLE statement. The .MYD file contains
the row data, and the .MYI contains any indexes belonging with
this table, as well as some statistics about the table. The data file contains
only row data, with minimal overhead.
Symlinking a database directory is common practice and can be used to store data on a different disk/partition for performance, safety and/or security purposes. From version 4.0 symlinking individual tables is also fully supported.
MyISAM actually offers a number of storage and indexing options within its basic file format. We will cover the ones that are most commonly used, so that we can compare them with each other and the characteristics of the other storage engines.
The MyISAM "fixed" row format is automatically selected if the table
structure does not contain any VARCHAR, TEXT or
BLOB type columns. In this case, each column has a fixed length,
and as a consequence, each row will be the same length. This means that if any
rows are deleted, they will only ever be replaced by rows of the exact same
length, so rows never become fragmented. Also, the storage engine will be able
to access individual rows by their "row number" instead of a complete file
offset. This makes any indexes smaller, and the overall system faster and more
memory efficient. Please note that the "row number" mentioned here is purely
internal, as rows in relational database tables are by definition
unordered.
The MyISAM "dynamic" row format is selected if a table definition contains
VARCHAR, TEXT or BLOB type columns.
Strictly speaking, this only applies to VARCHAR columns if the specified
maximum length is greater than three (3). In this storage format, rows may
occupy a varying amount of space. Free space created by deleted rows (or rows
that were updated and are now a smaller length) will, as before, be reused
— so while this format is very efficient in terms of storage space use,
fragmentation of rows may occur which can, over time, cause decreased
performance. Periodical maintenance (such as OPTIMIZE TABLE) is
therefore recommended. TEXT and BLOB data is stored
separately from the rest of the row data, so that an update of the other data
does not require the server to move around potentially very large
TEXT and BLOB type column data.
The MyISAM "compressed" row format is a read-only. Created from a regular
table using the myisampack tool, the compression ratio can be up
to 75%. Row data is still directly accessible, rows are individually compressed
using algorithms appropriate for each column type. This storage method is
particularly suited for archival of sales records, logs, or other periodical
data. It can also be useful for read-only data that is imported from an
external source. Compressed row tables can be stored on a CD or other read-only
media, and the MySQL Server can access them in that form.
The MyISAM storage engine currently incorporates three indexing methods:
BTREE, RTREE, and FULLTEXT. Normally,
BTREE indexes are used. RTREE indexes are used for
indexing geographical (GIS) data, and FULLTEXT indexes are
specifically tailored to the MySQL full text search system.
For concurrency control, MyISAM uses table-level locking with concurrent inserts. Let's spend a little bit more time on this, as it is often misunderstood. There are, in fact, three types of locks in MyISAM:
READ LOCAL lock. This is used by queries that
only need to read. This type of lock merely blocks updates, to prevent the data
from changing during the query. Other read queries can proceed, as can
concurrent inserts: if an INSERT statement can add the new data at
the end of the .MYD file, rather than by filling existing free
space (from rows that were deleted), it does not have to wait on a READ
LOCAL lock.
READ, or shared locks. This locking type
blocks updates, including all INSERTs. It is generally used if an
external tool such as myisamcheck needs to access a table file
directly.
WRITE, or exclusive locks. This is used by
DELETE, UPDATE and sometimes INSERT
statements. All other access (readers as well as writers) to the table is
blocked, to prevent updates from interfering with each other.
By "blocking" we mean that a thread (connection) may have to wait until another thread has completed its operation and releases the lock. While is is possible to set locks manually, the MySQL server employs the necessary locking implicitly for any statement it executes.
MyISAM does not support transactions. Effectively, this storage format
always operates in "AUTOCOMMIT=1" mode where each statement is
atomic. Please note that special constructs such as "INSERT ...
SELECT" and "CREATE TABLE ... SELECT" are regarded as
single statements. The isolation level is fixed, but would be equivalent to
"READ COMMITTED".
MyISAM index blocks are cached globally in the key buffer (i.e. all threads share that cache), for table data MyISAM relies on the caching of the operating system.
With its simple architecture, MyISAM offers high performance with low overhead in terms of memory and disk utilization.
Backups can be made using either mysqldump (SQL scripts) or
mysqlhotcopy (binary copy of the table files), both of which
require shared locks on the tables being backed up. In case of relationships
between tables, additional shared locking may be required to ensure consistency
of the backup.
In case of trouble, fixed-row format tables are easiest to recover, as the recovery tools know exactly how long each record is and where they can start. In the case of a system failure, generally only the indexes are affected. These can be easily rebuilt (even automatically), though this can take considerable time for larger tables.
MyISAM MERGE
A MyISAM MERGE table does not contain any data itself, but instead refers to
a number of identical underlying MyISAM tables. Operating like a UNION
VIEW, any query of the merge table may operate on one or more of the
underlying tables. Inserts are also possible. Typically, merge tables are used
when analyzing periodical data that is stored in multiple tables (these can
also be compressed tables, stored on a CD). Storing such data in a single table
is unpractical, both in terms of size as well as for management and
backups.
CREATE TABLE sales200401
(saleid INT UNSIGNED NOT NULL PRIMARY KEY,
dt DATETIME, INDEX (dt)) ENGINE=MyISAM;
CREATE TABLE sales200402
(saleid INT UNSIGNED NOT NULL PRIMARY KEY,
dt DATETIME, INDEX (dt)) ENGINE=MyISAM;
CREATE TABLE sales2004
(saleid INT UNSIGNED NOT NULL PRIMARY KEY,
dt DATETIME, INDEX (dt))
ENGINE=MERGE UNION=(sales200401,sales200402);
InnoDB
The InnoDB storage engine has a completely different architecture. InnoDB uses the concept of a tablespace, where all structure, table data and indexes are stored. A tablespace can consist of one or more files, even raw disk partitions. Recent versions of MySQL also offer an alternate mode, where InnoDB stores information belonging to a specific table in a single file, i.e. One file per table.
Concurrency control in InnoDB is handled by its complete support ACID transactions, multi-versioning, row-level locking, and foreign key constraints. For an in-depth discussion of these characteristics, see the article on "Concurrency Control".
Depending on the isolation level, InnoDB does not require any locking for a
SELECT. For updates, row-level locking is used. This makes
extremely high concurrency possible, with the following trade-off: InnoDB
requires about three times as much disk space compared to MyISAM, and for
optimal performance, lots of RAM is required for the InnoDB buffer pool. The
low-level locking mechanism that InnoDB uses has itself got very low memory
requirements and therefore does not require lock escalation, which so optimal
concurrency is maintained.
InnoDB uses BTREE indexes with a clustered primary-key.
Internally, InnoDB also automatically create hash indexes in RAM if it
recognizes specific common query patterns.
InnoDB's adherence to consistency and durability ensures that any committed transaction is stored somewhere on disk, either in InnoDB's internal "redo log", or inside the tablespace. On startup, recovery (after a system crash) is automatic: previously committed transactions that are still in the redo log are applied to the tablespace, and any uncommitted transactions are rolled back.
Backups can be made with mysqldump, which in the case of InnoDB
can be done without any locks. There is also a commercial InnoDB HotBackup tool
which can be used to take snapshots of the tablespace files.
Please note that in MySQL version 3.23, only the -Max binaries include InnoDB, and it needs to be specifically configured (from version 4.0, InnoDB is switched on and has a minimalistic configuration by default). On a running server, you can check whether InnoDB is installed by issuing the following query:
SHOW VARIABLES LIKE 'have_innodb'
In the result, you will see either YES (InnoDB is enabled and
has at least a basic configuration), NO (InnoDB wasn't compiled
in), or DISABLED (InnoDB is present in the binary but has been
disabled through the --skip-innodb option).
MEMORY (HEAP)
The MEMORY storage engine (or HEAP, as it was formerly called) keeps all table data in memory. Naturally this is very fast, but requires the availability of sufficient RAM, and when the server is shut down all the data in a MEMORY table will be gone. When the server is restarted, any existing MEMORY tables will be empty. So the table itself is persistent, i.e. MEMORY tables need to be explicitly dropped, just like other regular tables. Is it of course also possible to create a temporary memory table.
MEMORY tables offer fast HASH-based lookups when doing exact
searches on a full key such as:
SELECT... FROM htable WHERE a = 10;
From MySQL version 4.1, MEMORY tables can also have tree-based indexes, so that other lookup types are sufficiently fast on larger tables:
SELECT ... FROM htable WHERE a < 10; SELECT ... FROM htable WHERE t LIKE 'foo%';
MEMORY tables are globally visible for all server threads (connections), provided the user has the proper access permissions.
MySQL Cluster
MySQL Cluster, the latest addition to the family of MySQL products, uses highly advanced clustering technology that MySQL AB acquired from Ericsson Business Innovation in 2003.
NDB, the MySQL Cluster storage engine, does not directly manipulate data on a local storage medium, instead it connects to a cluster of database nodes, which can also be accessed by other MySQL servers. This allows for redundancy and scalability on a higher level.
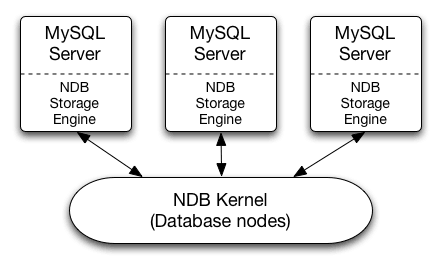
Cluster nodes are organized into groups. Table data is fragmented (partitioned) across the different groups. This aids speed, as each group is only required to handle part of the data rather than all of it.
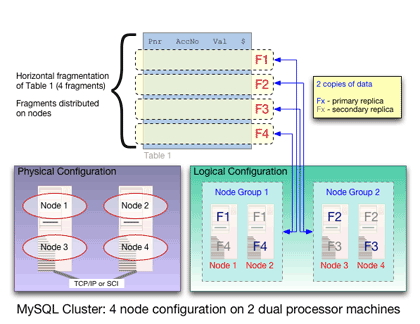
Synchronous replication is used between the nodes in a group, combined with a two-phase commit procedure across all groups.
While nodes keep their data entirely in memory for maximum performance, the durability requirement of ACID transactions is maintained by the cluster making sure that at least two nodes in each group have the a copy of the data. On-disk "redo" logs are maintained for recovery purposes., and each node requires sufficient disk space to store its entire fragment for cold starts.
MySQL Cluster can employ hash lookups as well as BTREE indexes
for data retrieval.
Because MySQL Cluster is main-memory based it is extremely fast. MySQL Cluster has good scalability by adding more memory and/or more nodes to a configuration.
MySQL Cluster tables should be used where very high speed, availability and redundancy are absolute requirements. Other tables (even in the same database) should use one or more of the other storage engines. This way the power and flexibility of MySQL server is used in an optimal manner.
In the last part of this series we will by compare key aspects of these storage engines and provide you with guidelines and practical examples to help you decide which engine may be best suited for a particular purpose.