About the Author

Arjen Lentz is a former Community Relations Manager at MySQL. He is currently the owner of Open Query and lives in Brisbane, Australia.

MySQL Storage Engine Architecture, Part 1: An Overview
MySQL Storage Engine Architecture, Part 1: An Overview
MySQL Server features a concept called storage engines, or table types. The server, and in fact the developer, can choose how and where a database table is to be stored based on which storage engine is best suited for a particular situation.
Programmatically this is nothing special, it is normal practice to divide a program into modules and layers. But it is unique for a DBMS (Database Management System), because a developer and even a DBA (Database Administrator) is traditionally insulated from the physical storage methods that the database server may employ. How the data is stored really does not concern them, as the server just takes care of everything. That being the case, a developer or DBA could benefit from knowing a bit more about such things as it may help them to optimize applications. This is an angle that may be applied to many aspects of database servers, but in this article we'll focus on the storage engines.
Why have a storage engine layer? There are a number of interrelated reasons, which we will now discuss.
Technology evolves. As new features are developed, maintaining backward compatibility in the file format is not always possible. Users, would need to run a conversion tool when they upgrade, or even dump/import their entire dataset. This is obviously very inconvenient. It would be much nicer if users could upgrade their server (for bug-fixes and other new features) without also having to migrate all their data. This means that a single version of the server has to support multiple file formats.
For server developers, changes in the data storage code may require related changes elsewhere in the server, and like with all new code there is always the possibility of introducing bugs. This calls for abstraction: changes in the underlying code, to a large extent, should not affect the code at higher levels.
Different applications have different requirements with regard to data storage, and some of these requirements may even conflict. Think of a banking application that requires highly secure transaction processing, versus traffic logging on a website. Typically, there are differences in the number and balance of selects and updates, as well as the need for transactions and isolation levels. There are always trade-offs, and choices need to be made. With only one mechanism available, most applications would just have to do with a solution that is probably not optimal for them. While accepting that there is no single tool suitable for every use, we think that there is something to be said for a moderate "Swiss army knife" style approach. It would be nice if a server can cater effectively to more than one type of application.
Fundamentally, different storage media call for a different approach. A hard disk has characteristics which differ wildly from RAM, for instance. In a nutshell, a hard disk can generally contain more data, but getting to it takes longer. RAM is very fast, but there is a limited supply of it. Some search algorithms are optimized for RAM, others are optimized for disk-based storage. And did you know that a Compact Flash card uses much more power when reading data? That is an issue that definitely needs to be considered for an embedded application. Who knows what other new technologies we will see in the future.
MySQL's storage engine architecture addresses all these aspects, and not by accident. It was a deliberate design choice by Michael "Monty" Widenius, MySQL AB's CTO.
Let us look at a simplified high-level diagram of the MySQL server architecture:
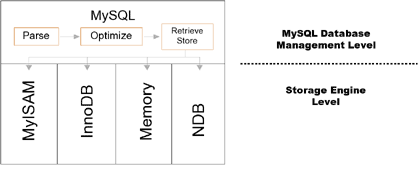
The diagram shows four storage engines, each with different characteristics:
- MyISAM is a disk based storage engine. Aiming for very low overhead, it does not support transactions.
- InnoDB is also disk based, but offers versioned, fully ACID transactional capabilities. InnoDB requires more disk space than MyISAM to store its data, and this increased overhead is compensated by more aggressive use of memory caching, in order to attain high speeds.
- Memory (formerly called "HEAP") is a storage engine that utilizes only RAM. Special algorithms are used that make optimal use of this environment. It is very fast.
- NDB, the MySQL Cluster Storage engine, connects to a cluster of nodes, offering high availability through redundancy, high performance through fragmentation (partitioning) of data across multiple node groups, and excellent scalability through the combination of these two. NDB uses main-memory only, with logging to disk.
One of the things that differs per storage engine is the locking and isolation mechanism, but most of the server operates in the same way no matter what storage engine is used: all the usual SQL commands are independent of the storage engine. Naturally, the optimizer may need to make different choices depending on the storage engine, but this is all handled through a standardized interface (API) which each storage engine supports.
So to a degree, the application does not need to know how its data is
stored. And it may not matter either, when the demands are not very high. But
for a larger dataset, or with more demanding access requirements, it does
become increasingly important to make a conscious choice. And the best news
is that an application can use multiple storage engines, as the selection can
be made on a per-table basis. Also, the server can convert tables between the
different formats using a simple ALTER TABLE command.
Replication
MySQL replication (asynchronous) works with all storage engines, as it is based on replicating SQL statements rather than possible storage-specific data. So, all table types can be replicated and will be the same type on replicated (slave) systems. It is possible to change the type of a table on a slave system, but this is generally not recommended. Also note that some data types (GIS, Unicode) is not supported by all storage engines.
MySQL Cluster uses synchronous replication internally, and multiple MySQL servers may connect to a single MySQL Cluster back-end. This technique may be used in addition to, or instead of, the asynchronous replication noted above.
Temporary Tables
It is possible to create a temporary table of any type. A temporary table is only visible to the current connection and will be destroyed when the connection is closed or the server is stopped.
CREATE TEMPORARY TABLE table1 (...) ENGINE=InnoDB; CREATE TEMPORARY TABLE table2 ENGINE=MEMORY SELECT * FROM table3 WHERE ...;
Temporary tables can be replicated like any other table, but it is recommended to use recent versions of MySQL server.
Default Storage Engine
If you use CREATE TABLE without specifying the
ENGINE=... option, the server will use the default. The default
storage engine is MyISAM. If you want to change the default to say InnoDB, you
can use the configuration directive
--default-storage-engine=InnoDB.
Something to be aware of is that if you create a table specifying an engine type that is not enabled, MySQL will automatically fall back to the default. From MySQL 4.1, a warning is issued.
Changing Existing Tables
You can change the storage format of an existing table.
ALTER TABLE t1 ENGINE=InnoDB; ALTER TABLE t2 ENGINE=HEAP;
These commands make the server create the proper table structure, indexes, and copy all the data. Do note that not all storage engines support all column and index types, so conversion is not practical in all instances.
In Part Two of this series we will take a more in-depth look at the features of the different storage engines that are available in MySQL Server. Part Three completes this series by comparing key aspects of the most popular storage engines and providing you with guidelines and practical examples to help you decide which engine may be best suited for a particular purpose.
Transactions, isolation levels and locking will be discussed in a separate article entitled "MySQL Concurrency Control."
In the near future, we will also publish an article detailing the Storage Engine API, effectively allowing you to "Roll Your Own Storage Engine"!