About the Author

Robin Schumacher is MySQL's Director of Product Management and has over 13 years of database experience in DB2, MySQL, Oracle, SQL Server and other database engines. Before joining MySQL, Robin was Vice President of Product Management at Embarcadero Technologies.

Understanding the Falcon Transaction Storage Engine – Part 3
In Part 1 of this article series, we looked at how the Falcon transactional storage engine was architected and how it compared to some of the other MySQL storage engines. Part 2 covered how Falcon handles transaction management and concurrency. In this final article in the series, I’ll look at how Falcon manages tables and indexes, and also cover backup/recovery along with migration topics.
Table Support in Falcon
In terms of storage, both tables and indexes are stored within the user datafiles that are automatically created by the Falcon engine when the first Falcon table is created in a database.
Falcon supports standard heap tables along with all datatypes available within MySQL. Tables can house up to four billion rows in the alpha release (this limit will be removed in the GA version). To support the auto-increment feature of tables, Falcon implements a subset of the standard SQL sequence feature. A sequence is a mechanism for generating unique ascending values that are not transactional. When a sequence is incremented, it remains incremented even if the action that causes the increment fails or the transaction rolls back. Falcon generates new sequences for concurrent inserts without requiring them to wait for each other. For users of Oracle and DB2, please note: Falcon sequences are not separate objects that can be addressed and manipulated as sequences in those RDBMS’s.
Foreign keys are not implemented in the alpha release of Falcon, but are planned for the GA release.
Falcon Indexes
With respect to indexes, Falcon uses an advanced form of B-tree indexing that provides a number of the benefits of clustered indexes without the drawbacks that come from the use of such structures. Traditional database index implementations traverse indexes by bouncing between index pages and database pages, which can oftentimes lead to inefficient or costly disk access.
Clustered indexes (or index-organized tables) are structured so that the physical ordering of records corresponds to the index order, with the actual leaf pages being the data pages. While some applications benefit from this organization, the physical implementation of clustered indexes can lead to space management problems, such as page splitting and more. Furthermore, a table can be clustered on only one index, reducing the efficiency of secondary indexes.
Falcon B-tree indexes work differently in that the index is scanned first, with bits being set in a sparse bit vector to indicate selected records. Records and data pages are then processed in bit order, which is also physical order on disk.
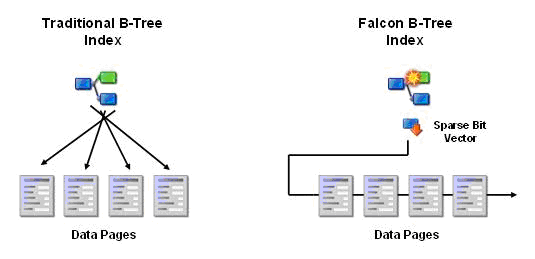
Falcon’s indexing scheme results in a number of benefits. First, all indexes behave like well-tuned clustered indexes. However, note that the data is not stored in index order. So, for example, doing a SELECT without an ORDER BY clause on a table with a Falcon index will not return data back in ascending index order (something you would see with an actual clustered index).
Second, index pages are locked, read, and released, with no intervening data accesses that can cause locking conflicts.
In addition to specialized B-tree indexes, Falcon also employs what are currently called “index accelerators”. To reduce the cost of adding lots of index entries, Falcon implements in-memory index regions that buffer index changes in memory until a commit. Because all the index changes made by a transaction are applied in sorted order, Falcon avoids making scattered changes throughout the index. Adding a single large block to the serial log is also faster than adding numerous small blocks. Index accelerators improve the performance of bulk loads and mass updates or inserts on existing tables.
When a Falcon transaction makes a change that affects an indexed field, it creates an entry in a private in-memory index section for that index. Each transaction that inserts or updates indexed fields has a private in-memory section for each index it changes. The segments are linked in memory to the primary index definition and to the transaction that created them. The in-memory index has the same structure as the permanent B-tree. When a transaction commits, all changes it made to each index are written to the log as a single entry. The log entry contains a sorted list of the new entries for that index, effectively the bottom level of the in-memory index. When one of the worker threads applies the changes to the index, having them in sorted order means that all changes to a bottom level page of the index are together. Therefore, splits are propagated to one upper level page at a time. When an index segment has been copied from the log to the permanent index, the in-memory copy of the segment is released.
When doing an index lookup, a transaction looks in the permanent index, and in its own in-memory index section for that index, and in the private index segments of any transaction that has committed but remains in memory. As a result, a transaction may find two entries for the same value of the same row, one from the permanent index and one from the in-memory segment of a committed transaction. Since the two resolve to the same record, and since Falcon uses a two-phase index lookup with an intermediate bit map, the additional cost is minimal.
For inserts and updates of unique and primary key indexes, and for referential constraint evaluation, Falcon must verify that there are no conflicts with committed or uncommitted data. Those checks are handled by referencing the permanent index and all in-memory index segments for that index.
One last thing regarding indexes: online add/drop index capability is planned for the first GA release of Falcon.
Falcon Backup and Recovery
Most MySQL users use the bundled mysqldump utility to backup their databases, although some rely on open source alternatives or third party backup tools. Using mysqldump is typically very easy and efficient for most databases; however it should be understood that the utility can be impractical for extremely large databases or MySQL installations that utilize multiple storage engines and require no business interruption.
There are two basic ways to backup a Falcon database with mysqldump:
- Run
mysqldumpusing the command line. - Use the graphical MySQL Administrator tool that uses mysqldump behind the scenes.
To use mysqldump from the command line to backup a Falcon database called gimf, you could enter something similar to this:
mysqldump -uroot --port=3309 --extended-insert --quick gimf > gimf.dmp
The above command specifies the ‘root’ user along with the port the MySQL instance is running on. It also specifies that the extended insert option be used, which uses MySQL’s multi-insert feature to more quickly restore a database if needed. It also uses the –quick option, which assists with large tables, and also specifies the database being backed up (gimf). Finally, it pipes the output to the actual backup file.
The same operation can be performed with the MySQL Administrator tool (which can be downloaded in the MySQL management tools bundle found at http://dev.mysql.com/downloads/gui-tools/5.0.html). Using MySQL Administrator – which now supports Falcon – makes knowing the various mysqldump options unnecessary as everything is handled in point and click fashion. Simply log into the database server with MySQL Administrator, select the Backup option in the Explorer pane, choose the option to create a new backup project, select the database(s) containing the Falcon tables you want to backup, and press the Execute button.
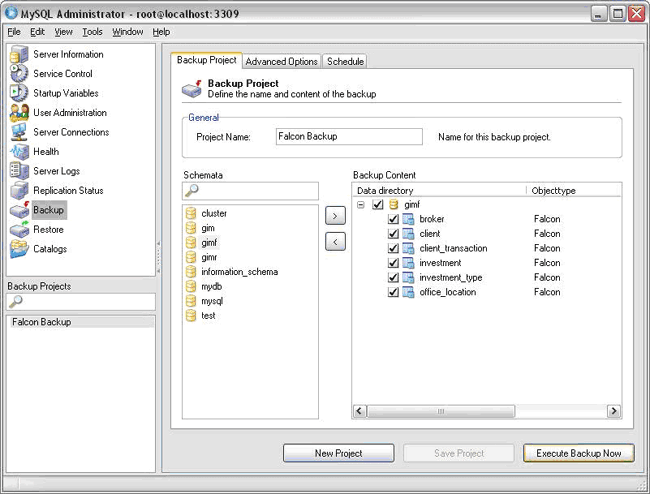
Falcon will support the --single-transaction option of mysqldump in the GA release so online backups can be performed. And when the new online backup capability of MySQL is ready to ship, Falcon will fully support that.
Restoring a Falcon database is no different than restoring any other storage engine. A mysqldump file can be piped in via the mysql command line tool, or you can use the MySQL Administrator to do point-and-click restores of Falcon databases.
Migrating to Falcon
One of MySQL’s strengths is being able to easily migrate databases between the different storage engines that make up the pluggable storage engine architecture of the server. This means that you can start with one particular engine and then switch to another (and another) as your needs change. Current MySQL tables can easily be migrated to Falcon via the ALTER TABLE … ENGINE=FALCON command. Of course, you need to keep in mind a few migration considerations such as:
- True clustered indexes on InnoDB tables would not be migrated and function on Falcon as they do on InnoDB.
- Applications requiring the use of the Read Uncommitted lock isolation level cannot use Falcon, as it does not support Read Uncommitted.
- Minor locking differences in InnoDB may cause some applications to behave differently with Falcon. However, most InnoDB applications will experience no problems.
- GIS indexes on MyISAM tables cannot be migrated to Falcon (Falcon supports GIS datatypes but not GIS indexes).
- Full-text indexes on MyISAM tables cannot be migrated to Falcon.
- Custom data directories for datafiles used for the MyISAM and Archive engines cannot be maintained for objects migrated to Falcon.
- Row-level replication (instead of statement-based replication) is required when replicating Falcon objects.
Migrating most any non-MySQL database to a MySQL server is easily handled through the use of the MySQL Migration toolkit. Migrating a database that is on Oracle, SQL Server, Sybase, Microsoft Access, or pretty much any RDBMS that can be accessed via a JDBC connection can be graphically performed in the Migration toolkit.
Migrating a non-MySQL database to Falcon using the Migration Toolkit can be done by following these steps:
- Download the Migration Toolkit, which is contained in the MySQL management tools bundle found at http://dev.mysql.com/downloads/gui-tools/5.0.html. Installation should take only a minute or two.
- Connect to the Source database.
- Connect to your target MySQL server that contains the Falcon engine.
- Select the schemas/tables from the source database you want to migrate to Falcon.
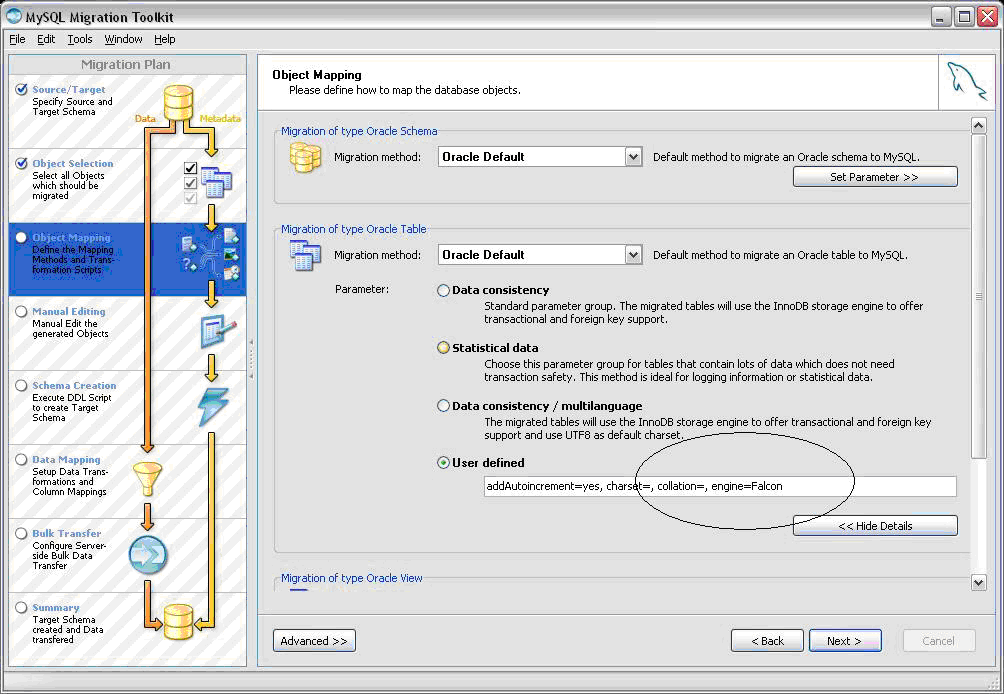
- When you reach the part of the migration wizard where you are asked to specify the migration of the MySQL tables (the Object Mapping screen), you will need to click on the “Set Parameter” button in the “Migration of Type … Table” section. Once you do this, click on the “User defined” radio button and then change the default ENGINE= parameter value to “falcon”.
- Continue with the rest of the migration wizard until you have successfully migrated your database over to Falcon.
Note that the Migration Toolkit can also be used to migrate MySQL databases located on one physical server to another MySQL database located on a different (or same) server.
Conclusion
We’ve reached the end in this quick introductory series of articles on the Falcon transactional storage engine. I hope that you will download and try out Falcon, and of course, let me know what you think (both good and bad). You can download a binary for Linux and Windows at http://dev.mysql.com/downloads/mysql/6.0.html and also compile from source if you’d like. And don’t forget to visit the Falcon forum to post questions and such.
Thanks, as always, for supporting MySQL!