About the Author

Robin Schumacher is MySQL's Director of Product Management and has over 13 years of database experience in DB2, MySQL, Oracle, SQL Server and other database engines. Before joining MySQL, Robin was Vice President of Product Management at Embarcadero Technologies.

Understanding the Falcon Transaction Storage Engine - Part 1
If you've been using MySQL for any time at all, you know that a unique advantage afforded MySQL users is the ability to use multiple storage engines to manage the underlying data stored on the server. This efficient and modular architecture provides large performance and manageability benefits for those wishing to specifically target a particular application need - such as data warehousing, transaction processing, high availability situations, etc. - while enjoying the advantage of utilizing a set of interfaces and services that are independent of any one storage engine. The MySQL server supplies engines that are internally developed, provided by third-party software vendors, and also allows a user to build their own storage engine if they desire.
Some of MySQL's engines support transaction processing and some do not. The current production engines in MySQL 5.0 that support transaction management are NDB/Cluster, InnoDB (supplied by Oracle), and the solidDB engine (supplied by Solid Information Technology). MySQL has also just introduced a new transactional storage engine - code named Falcon - that is currently available in an alpha release. Falcon is a next-generation transactional management engine designed to run on all popular hardware/architecture platforms, but it is especially designed to take advantage of the large memory caches available in 64-bit environments. Falcon is a natural fit for modern businesses and always online applications that need lightening-fast transaction performance and rock-solid data reliability.
In this first in a series of short articles on the Falcon engine, let's take a look at how Falcon has been architected and see how it differs from some of the other popular MySQL storage engines.
Falcon Architecture
The MySQL Falcon architecture is both an advanced and simplified design that makes for a high performing transactional database that requires little maintenance or troubleshooting on the part of database administration staff. The architecture of the Falcon engine is depicted in the figure below:
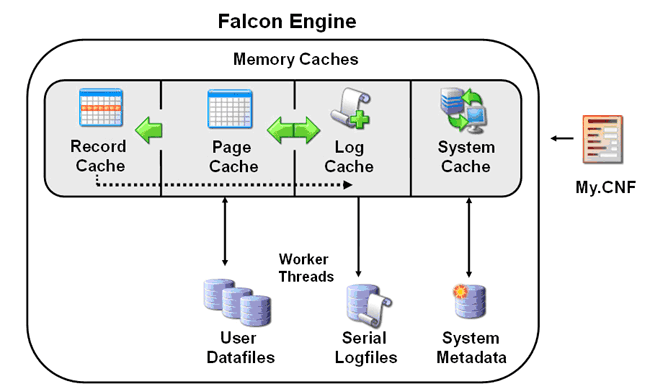
The architecture consists of seven basic components:
- User tablespaces - contains the actual user data and indexes stored in a Falcon database.
- Falcon serial log - contains recently committed data changes, index changes, and transactional information. The log also handles crash recovery activities for a database.
- Page cache - memory region that holds database pages being read or written.
- System metadata - Falcon's system tablespace that holds internal information.
- Record cache - memory region that holds copies of active and uncommitted records.
- System cache - memory region that contains transaction context information, index accelerators, and system metadata.
- Worker threads - moves data from the Falcon Log into the database page cache, from the page cache to disk, and performs BLOB management.
Each of these components is covered in more detail in the following sections.
Falcon Storage
Falcon offers a number of storage features that include self-balancing indexes, auto-growth of both data and log files, automatic reclamation of space released by deleted records both on data pages and in indexes, and page reorganization to consolidate free space.
Storage for User Data
In the alpha version of Falcon, the engine creates a system tablespace to hold internal engine information and a default user tablespace for user-defined objects. Currently, Falcon user tablespaces contain all Falcon tables, BLOBs, and indexes defined for databases that hold Falcon objects. DBAs and developers can create user tablespaces in any directory or filesystem they would like and place tables into them via DDL.
The underlying datafiles of Falcon tablespaces offer automatic storage extension when needed and automatic space reclamation, which makes reorganizing tables and indexes mostly unnecessary.
Page sizes in Falcon are assigned at MySQL instance initialization time and cannot be altered. Page sizes can range anywhere from 2K up to 32K, with 4K being the default. The parameter that controls this is falcon_page_size.
Rows are stored densely on pages, with updates that increase row length being automatically handled by Falcon so DBAs need not bother with creating periodic defragmentation jobs, which can block access to data when the job is running.
The maximum storage size for a single tablespace current stands at over 100TB (around 116TB), which should be sufficient for the vast majority of application needs.
The Falcon Log
Besides primary data storage, Falcon uses another storage structure called the Falcon Serial Log to manage write-ahead logging and crash recovery. Two physical files actually make up the Falcon Log. Log entries are variable length blocks, which are read and written in one megabyte extensions. Each block has a header that includes a unique 64-bit identifier, the length of the block, the creation time of the database to which it belongs, and the block number of the oldest unapplied block in the log file. A block in a log is "applied" if all committed data in the block has been transferred to the database. Blocks are written to the first Falcon Serial Log file until it fills its first extension, after which a second file is created. New log entries are then applied to the second file, which will automatically extend, one megabyte at a time, to accommodate transaction demand.
As transactions commit, the blocks that hold their data are applied from the files to the database. Once all the blocks in the first file have been applied, the next extension of the log reopens the first file and starts overwriting it. The second Falcon Log file is closed for entries and its data is applied to the database until it is completely applied. Each time a log file is extended, Falcon checks to see whether the other file is completely applied. If so, it switches files. This process continues in this round-robin fashion.
One distinct aspect of the Falcon Log is that data created by uncommitted transactions never appears in the log, so the log does not serve as an "undo" or rollback mechanism for data changes. Simply put, only data that is intended to be found in the database ever makes it to the Falcon Log. What this practically equates to are near-instantaneous rollbacks and very fast crash recovery times.
Crash recovery in the Falcon engine is handled by the Falcon Log, with data from committed transactions that have not been applied to the user datafile (prior to a system crash) being written to the database upon restart of the system. The serial log also contains internal structural information about page allocations and releases, index page splits, record number and blob allocations and releases, etc. used in recovery.
The Falcon Log's physical location is defaulted to the data directory of the database, but can be changed by the DBA to be somewhere else on the server, which helps reduce I/O contention at the disk level. Note that custom-defined Falcon log locations are not available in the alpha release, but will be supported in the GA version.
Falcon Memory Caches
Falcon was designed to perform best on systems with generous amounts of memory. Although the memory caches utilized by Falcon are similar in some respects with other RDBMS's and MySQL engines, the cache structures offer a number of improvements over traditional memory caching strategies. The mechanisms used by Falcon with respect to memory caching include:
- Log Cache - log information is kept in memory and flushed to the Falcon Log when transactions commit. Falcon keeps eight windows into the log file for reading and writing, and each window is 1MB. The
falcon_log_file_memory_useparameter in the my.cnf file controls the amount of memory devoted to the Falcon log cache. This parameter is not available for alpha but will available in the GA release. - System and Index Cache - data needed by Falcon (table and field definitions, transaction state, etc.) are also maintained in memory for quick reference. In addition, local index accelerators represent index segments created by a running transaction are also stored in the system memory. When a transaction changes indexed fields, it builds an index accelerator section in system memory, representing its changes. On commit, all index changes for the transaction are written to the Serial Log in sorted order and later merged with the permanent index by the worker thread.
- Page Cache - database pages read from disk for a particular database. The page cache size is controlled by the
falcon_page_cache_sizeparameter, the default of which is 4MB, and is set in the my.cnf file. Although record and index changes go to the serial log before being written to database pages, blob data is written directly into the page cache. This avoids logging large data items that are rarely referenced or changed by the transaction that creates them. - Record Cache - the record cache is a memory region devoted to holding rows that have been requested by end-user queries for a particular database or created by active transactions. Note that this cache differs from traditional data caches in that only specific rows needed by applications reside in the cache as opposed to entire data pages (which may contain only subsets of needed information). The record cache can hold several versions of records that have been modified or deleted. This technique guarantees that active data needed to satisfy user requests is in memory, shortens row access time, and reduces cache bloat by not including un-requested information. The record cache also assists in supporting the multi-version concurrency control (MVCC) mechanisms of the Falcon engine. The record cache is controlled by two parameters. The
falcon_min_record_memoryparameter (default 10MB) determines the minimum amount of RAM supplied to the record cache, and thefalcon_max_record_memory(default 20MB) limits the total amount of memory available to the cache.
Because of the support the record cache supplies to transactions, a scavenge thread is used to ensure only "hot" data resides in the cache. When the falcon_max_record_memory limit is reached, Falcon surveys the demographics of the generational data in the cache, and removes the oldest generations. This process is more complicated than the standard LRU algorithm used by many database systems, but it is faster and more efficient.
Falcon Worker Threads
Falcon has four worker threads. The first is called the "gopher" thread. Its sole function is to move committed data changes from the log to data pages and to merge logged index changes with the permanent version of the index stored in the database. The second thread handles the periodic flushing of the page cache and scavenges the record cache.
The third worker thread is called the page writer thread and it is used to write out blobs before page commit to the user datafiles. The fourth thread is the scheduler thread and, as its name implies, it schedules a variety of things like to occur like record scavenging, page flushing, and checkpoint operations.
Of course there are other server threads that exist above the storage engine layer that communicate with Falcon, but these are independent of the actual Falcon architecture.
Conclusion
Falcon's architecture is one of advanced design, but also one that's easy to understand and an implementation that pretty much takes care of itself so you don't have to. The next article in this series will focus on how Falcon manages tables and indexes, so be sure to look for that soon. In the meantime, please download the latest Falcon alpha release and let us know what you think. You can download a binary for Linux and Windows at http://dev.mysql.com/downloads/mysql/6.0.html and also compile from source if you'd like.
Thanks, as always, for supporting MySQL!