In diesem Abschnitt wird beschrieben, wie MySQL Cluster mehrfach vorhandene Daten für die Speicherung aufteilt.
Die Konzepte, die im Folgenden mit kurzen Definitionen aufgelistet werden, sind für das Verständnis dieses Themas unerlässlich:
-
(Daten-)Knoten: Ein ndbd-Prozess, der eine Replik speichert, also eine Kopie der Partition (siehe unten), die der Knotengruppe, zu welcher dieser Knoten gehört, zugewiesen wurde.
Normalerweise liegt jeder Datenknoten auf einem anderen Computer. Es ist jedoch möglich, mehrere Datenknoten auf einem einzigen Computer unterzubringen, wenn dieser über mehrere Prozessoren verfügt. In solchen Fällen kann pro physikalische CPU eine ndbd-Instanz laufen. (Beachten Sie, dass ein Prozessor mit mehreren Zentraleinheiten immer noch ein einzelner Prozessor ist.)
Die Begriffe „Knoten“ und „Datenknoten“ werden im Zusammenhang mit ndbd-Prozessen synonym verwendet. Wenn Management-Knoten (ndb_mgmd -Prozesse) und SQL-Knoten (mysqld-Prozesse) gemeint sind, wird dies im Text ausdrücklich gesagt.
-
Knotengruppe: Eine Knotengruppe besteht aus einem oder mehreren Knoten und speichert eine Partition oder eine Menge von Replikas (siehe nächster Eintrag).
Hinweis: Gegenwärtig müssen alle Gruppen in einem Cluster gleich viele Knoten haben.
Partition: Ein Teil der in einem Cluster gespeicherten Daten. Es gibt so viele Cluster-Partitionen, wie Knotengruppen im Cluster vorliegen, und jede Knotengruppe ist dafür verantwortlich, mindestens eine Kopie der ihr zugewiesenen Partition (also mindestens eine Replik) aufzubewahren, die dem Cluster zur Verfügung steht.
Replik: Eine Kopie einer Cluster-Partition. Jeder Knoten in einer Knotengruppe speichert eine Replik. Wird gelegentlich auch als Partitionsreplik bezeichnet.
Das folgende Diagramm zeigt einen MySQL Cluster mit vier Datenknoten in zwei Knotengruppen zu je zwei Knoten. Beachten Sie, dass hier nur die Datenknoten gezeigt werden, obwohl ein funktionierender Cluster einen ndb_mgm-Prozess für das Cluster-Management und mindestens einen SQL-Knoten für den Zugriff auf die im Cluster gespeicherten Daten benötigt.
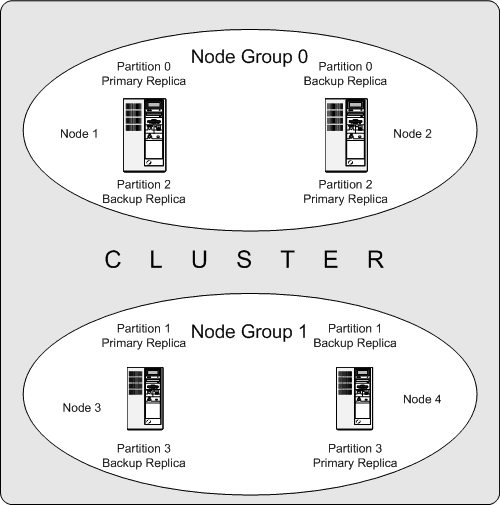
Die in diesem Cluster gespeicherten Daten sind auf vier Partitionen verteilt, die mit 0, 1, 2 und 3 nummeriert sind. Jede Partition wird – in mehrfachen Kopien – in derselben Knotengruppe gespeichert. Partitionen werden auf unterschiedlichen Knotengruppen gespeichert:
Partition 0 wird in Knotengruppe 0 gespeichert; eine primäre Replik (oder primäre Kopie) wird auf Knoten 1 gespeichert, und eine Backup-Replik (Backup-Kopie der Partition) auf Knoten 2.
Partition 1 wird auf der anderen Knotengruppe gespeichert (Knotengruppe 1); die primäre Replik dieser Partition ist auf Knoten 3 und die Backup-Repli befindet sich auf Knoten 4.
Partition 2 wird auf Knotengruppe 0 gespeichert. Die Platzierung ihrer beiden Repliken ist jedoch genau umgekehrt wie bei Partition 0: Bei Partition 2 wird die primäre Replik auf Knoten 2 und die Backup-Replik auf Knoten 1 gespeichert.
Partition 3 wird auf Knotengruppe 1 gespeichert, und die Platzierung ihrer beiden Repliken ist umgekehrt wie bei Partition 1. Mit anderen Worten befindet sich ihre primäre Replik auf Knoten 4 und die Backup-Replik auf Knoten 3.
Für den Dauerbetrieb eines MySQL Clusters bedeutet dies: Solange jede Knotengruppe des Clusters mindestens einen funktionierenden Knoten hat, ist der Cluster im Besitz einer vollständigen Kopie sämtlicher Daten und bleibt funktionstüchtig. Dies wird im nächsten Diagramm veranschaulicht.
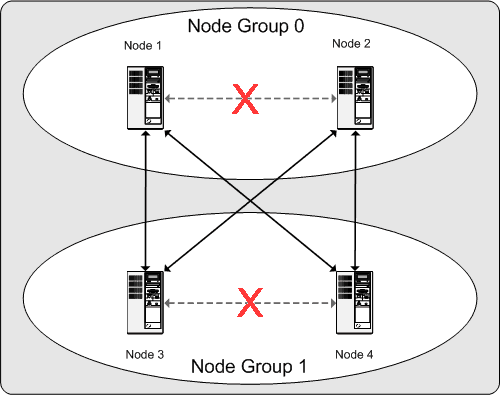
In diesem Beispiel, in dem der Cluster aus zwei Knotengruppen mit je zwei Knoten besteht, genügt eine beliebige Kombination mindestens eines Knotens aus Gruppe A und mindestens eines weiteren Knotens aus Gruppe B, um den Cluster „am Leben“ zu halten (wie es die Pfeile im Diagramm zeigen). Wenn jedoch beide Knoten einer Knotengruppe versagen, genügen die verbleibenden beiden Knoten nicht, um den Betrieb aufrechtzuerhalten (dies zeigen die mit X markierten Pfeile). In beiden Fällen hat der Cluster eine vollständige Partition verloren und kann somit nicht mehr auf alle Cluster-Daten Zugriff geben.
Dies ist eine Übersetzung des MySQL-Referenzhandbuchs, das sich auf dev.mysql.com befindet. Das ursprüngliche Referenzhandbuch ist auf Englisch, und diese Übersetzung ist nicht notwendigerweise so aktuell wie die englische Ausgabe. Das vorliegende deutschsprachige Handbuch behandelt MySQL bis zur Version 5.1.