
MySQL Wizardry
|
By Giuseppe Maxia |
|
The golden rules
"Rule number one:" -- wizards have always a rule n. 1 for everything -- "cross-tabulating is a simple algorithm with a complex implementation. Once you know the principle, you can do everything you need for your statistics. The difficult part is making the process automatic. You don't know in advance which values you should use for your columns. Hence, you have to find such values every time, before creating the second query. The real problem with cross-tabs is that there are no simple cases. Even the ones that look as such, have sticky problems. And you should consider this as rule number two."
I was about to lose heart, but he had more for me.
"On the other hand," he continued, "This algorithm is so flexible that will let you do things that your ordinary spreadsheet won't let you. For example, let's suppose that you want a x-tab with the number of employees by gender and the total of their salaries as well. In your common graphical tool you can do either of them. With this system, you can combine both. It's no difficult, just complicated. Now, if you fetch some more coffee, I'll show you."
And when I came back from the kitchenette, there it was.
mysql> SELECT location
-> , SUM(IF(gender='M',1,0)) AS M
-> , SUM(IF(gender='M',salary,0)) AS salary_M
-> , SUM(IF(gender='F',1,0)) AS F
-> , SUM(IF(gender='F',salary,0)) AS salary_F
-> , COUNT(*) AS empl
-> , SUM(salary) AS tot_salary
-> FROM locations INNER JOIN employees USING (loc_code) GROUP BY location;
|
He took a sip from his mug and added, "And of course nobody could prevent you from inserting a totally unrelated line into your query, like this one:"
mysql> SELECT location ,SUM(IF(gender='M',1,0)) AS M
-> , SUM(IF(gender='M',salary,0)) AS salary_M
-> , SUM(IF(gender='F',1,0)) AS F
-> , SUM(IF(gender='F',salary,0)) AS salary_F
-> , SUM(IF(dept_code = "4", 1,0)) AS `Sales`
-> , COUNT(*) AS empl
-> , SUM(salary) AS tot_salary FROM locations
-> INNER JOIN employees USING (loc_code) GROUP BY location;
|
"Here we have results coming from three different sources: the counting of employees by gender, the sum of their salaries by gender, and the total number of the employees in the Sales department, regardless of their gender. I know that this particular example doesn't make much sense, but this is something that people in the management, for reasons that completely escape my intellectual hold, want to put together. Don't underestimate such possibility, which could prove to be useful in many occasions."
I knew by then that his enthusiasm was growing thinner, and I should have expected him to leave abruptly any moment. I had to refuel his good disposition and ask some juicy questions.
"This is really wonderful," I said, "but in a real application you would not use SQL alone. How can I implement this algorithm with a general purpose language?"
Putting the pieces together
The wizard startled, as if awaken from a troubled sleep and suddenly his eyes were sparkling with renewed interest.
"Yes, of course," he replied. "If we stick to one-level cross-tabulations, this algorithm will fit nicely into any high level language. We should avoid the multi-level ones, for the moment, because the general concept is more important than the thorny details. Let me draw you a flow-chart diagram."
I had already relinquished my desktop, and I stayed quietly at his side, while he was skillfully drawing this diagram, which he explained almost as fast as he was designing.
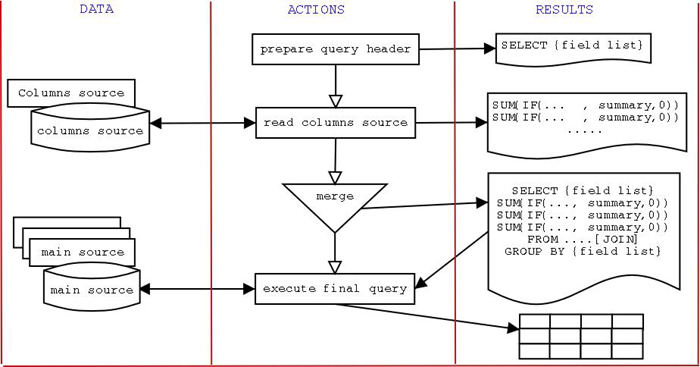
"The required actions are quite simple. However, you need some planning before starting. First, you have to identify the source for the columns. It could be the same source from where you need to count or sum, but in a well organized and normalized database it should be in a separated table. Either way, your first action with the database will be to query for distinct column values. Then you will merge such values within the summary statements composing your query. And at that point you'll be ready to execute. You can only omit the initial query if you are 100% sure that your values have not changed. This could be the case, for example, if your column values are in a read-only table. But usually this is not the case, or else cross-tabulations wouldn't be that hard. Well, let's start. Any preferred language?"
This was a false democratic question, which I knew by experience. I could mention any language and he would be proficient in it, but he would reject on some ground, until I would eventually manage to name the language he had in mind. Having gone through the motions before, I had my answer ready:
"I think that Perl would serve the purpose," I said hastily.
He nodded, approving my wisdom, and fired a copy of vim from a xterm.
"Sorry if you are an Emacs guy," but his voice betrayed his complete lack of sorrow, "Nothing like vim to highlight Perl syntax. I am sure you can follow me into this, and besides, I have the helm."
That, I knew for sure. My computer was firmly in his possession, and I started doubting that I would ever have it back. The wizard, unaware of my anxiety, was already writing:
#!/usr/bin/perl -w use DBI; use strict; |
(note: You can check here the full script, with plenty of comments).
Now, you would expect your average wizard to be adventurous and careless, keen of programming without constraints. Not this one. My wizard is a wizard because he behaves like one, but, being a database wizard, he is also very strict in matter of coding. More than once he gave me a speech on the importance of catching the errors in advance, before they can catch you. Since I knew that lecture by heart, I did not comment. My only contribution was to provide the IP address of my server and the location where the DBI could look for my user-name and password. I suspect that the wizard already knew that much, but he wanted to make me feel important by letting me provide some tiny contribution to the script.
my %params;
while (<>) { # gets the configuration from the input pipe
next if /^#/; # skips comments
my ($name,$value) = split '=',$_;
chomp $value;
$params{$name} = $value ;
}
$params{database} or die "no valid input given\n";
|
"We are going to read the parameters into a hash from a configuration file. They are too many for the command line, and it's better to save them to a file, which will be even clearer. In a production case, you would rather store those parameters into a database table. Four our purposes, we are going to use a text file. Actually, let's write it down, before we continue. I think it would be better to start with the simple case, location by gender."
title=location-gender database=xcompany row_name=location row_alias=town col_name=gender col_alias=gender col_value=1 col_from=FROM employees col_where= col_order= row_from=FROM locations INNER JOIN employees USING(loc_code) row_where= row_order=ORDER BY loc_sort_order row_group=group by location |
He saved those parameters into a location-gender-count.xtab and explained:
"See, our parameters are the description of the final query. In order to build the query, we need to set its parts. In this particular case, we are not going to use a WHERE and a ORDER BY clause for the columns, but you know that we may need them for the others, so we'll leave them. Our parsing mechanism can easily take care of the empty strings. In this script I assume that all these parameters are properly set in the configuration file. I will skip all the error checking on that, and you can implement it later on."
my $dbh = DBI->connect("DBI:mysql:$params{database};"
."host=172.16.35.1;mysql_read_default_file=$ENV{HOME}/.my.cnf")
or die "can't connect $! \n";
|
"This is fairly simple. Just the connection to the database. Now we have a database handle $dbh and with it we can go for the first query."
my $row_statement = "";
my $sth = $dbh->prepare("SELECT DISTINCT $params{col_name}, $params{col_alias} "
. $params{col_from} . " " . $params{col_where} . $params{col_order});
$sth->execute();
while (my ($colname, $colalias) = $sth->fetchrow_array()) {
$row_statement .= ", SUM(IF($params{col_name} = \"${colname}\","
. " $params{col_value}, 0)) AS `${colalias}` \n"
}
$sth->finish();
$dbh->disconnect();
|
I recognized the proceedings. He was instructing Perl to do the same thing that he was previously doing manually. I told him that much.
"Yes, exactly," he approved. "And in addition to that, using a high level language will grant us some more freedom. Since we have already collected the field list from our configuration file, we are not in a hurry to compose our second query. Having the parameters in a hash will also give us some amount of control, since any missing parameter from the configuration file will be duly reported by the Perl compiler. At this point, the only thing we need to do is to gather all the pieces together and produce our final query."
# ------------ add total column and row details
$row_statement .= ", "
. (($params{col_value} eq "1")? "COUNT(*)" : "SUM($params{col_value})")
. " AS total \n"
. $params{row_from}
. $params{row_where} ;
print "use $params{database};\n";
$row_statement =~ s/\n\n/\n/g; # remove double EOL
print "SELECT $params{row_name} AS $params{row_alias} \n",
"$row_statement\n$params{row_group} \n $params{row_order} ;\n"; # cross table
print "SELECT 'TOTAL'\n$row_statement;\n"; # the total line
|
He continued explaining.
"Since you have seen the manual examples and the flow-chart, what we are doing shouldn't come as a surprise to you. We add a total line, which will be a real SUM or a COUNT, depending on the parameter that was entered. Then we add the FROM and WHERE clause, and we don't care if this last one is empty. The resulting script will include a USE database statement, followed by a query that should look much like the one we entered manually with cut-and-paste."
I wanted desperately to enter the discussion, so I told him what was troubling me.
"Why you did not complete the $row_statement with the GROUP and ORDER-BY clauses? Why did you stop at the WHERE level?"
Almost annoyed by my lack of insight, he replied "You should see it by yourself. The $row_statement as I made it is what we have in common between the normal selection and the total line. To get the grand total you should not GROUP, and since we are going to get only one line, it doesn't make much sense to ORDER it. Does it? Now, since you mentioned the total, this solution is just for a quick demonstration, which I can do with a single line of Perl. If your tables are those big babies with millions of record that you might have in your data warehouse, then you'd better send the output of this query to a temporary table and then get the grand total from there. For tables with less than one hundred thousand records, MySQL will slurp this kind of cross-tabs in a blink."
He got up from my chair, and I knew that my lesson was over.
"Wait a minute." I said hastily. "This script doesn't execute the cross-tab query. How do you use it?"
Still halfway from my chair, he bent to the keyboard, and typed:
$ perl xtab.pl < location-gender-count.xtab | mysql -t |
"Just add your password and host, if you need it, and it will give you the X-tab."
"But? wait! I have a few questions about multi-level cross-tabulations."
He smiled in a devilish way.
"I am sure you do. But I have a girlfriend who wants to discuss database theory with me," he looked at his watch and added "in exactly ten minutes at that new Chinese restaurant downtown, and I shouldn't make her wait. I think you have enough food for thought to fill your weekend. Give me a call next week, and perhaps, if I can spare half an hour, I can give you a hand."
And while offering his metaphoric limb, he extended his real one to shake mine, and off he went before I could say 'son of a wizard!'.
 |
DevShed.com is the independent Open Source Web Development Site. Fresh tutorials, articles and discussion of MySQL, PHP, Perl, Python, Apache, JSP and administration can be found daily at http://www.DevShed.com/ This article is Copyright 2001 by Developer Shed, Inc. All rights reserved. Reproduced with permission. |