About the Author

John David Duncan is a consulting engineer with MySQL Inc., and lives in San Francisco, CA.

A look at MySQL on ZFS
Contents
- 1 A look at MySQL on ZFS
About ZFS
When Sun Microsystems released the ZFS filesystem in 2004, they set out to remove all of the practical limits on filesystem storage, and to make the arcane details of storage management a thing of the past. ZFS is a 128-bit filesystem with – to name just a few features – copy-on-write transactional semantics, fast snapshots, and optional compression.
The most obvious benefit of ZFS is its simple administration. In ZFS, traditional tasks like formatting a disk or editing /etc/fstab are gone entirely, and building a mirrored or striped RAID can be accomplished with a one-line command that actually looks sensible, is easy to remember, and has interactive help. ZFS does for storage management what MySQL did for databases, and like MySQL, it's open source, as well. ZFS was first introduced in Solaris, but Linux ports are underway, Apple is shipping it in OS X 10.5, and it will be included in FreeBSD 7. For more details on ZFS in general, see the ZFS Community page at opensolaris.org.
Most ZFS administration relies on two commands: zpool, for managing storage pools, and zfs, for filesystems. The storage pool is a key abstraction: a pool can consist of many physical devices, and can hold many filesystems. Whenever you add storage to the pool, it becomes available to any filesystem that may need it. To take a newly-attached disk and use the whole disk for ZFS storage, you would use the command
# zpool create zp1 c2t0d0
Here, zp1 represents the name of a pool, and c2t0d0 is a disk device. If the Solaris-style volume name looks unfamiliar, note that on Linux and other OSes, the commands will use native device names.
If you have a disk had already been formatted – say, with a UFS filesystem on one partition – you can create a storage pool from another free partition:
# zpool create zp1 c2t0d0s2
You can even use a plain file for storage:
# zpool create zp1 ~/storage/myzfile
Once you have a storage pool, you can build filesystems on it:
# zfs create zp1/data # zfs create zp1/logs
Don't imagine waiting for newfs after typing those commands, though, because they run just about instantaneously. Later on, if you run out of space, just add another device to the pool, and the filesystem will grow.
# zpool add zp1 c3t0d0
ZFS and Tablespaces
To appreciate what this might mean for MySQL, consider the problem of storage management under InnoDB.
innodb_data_file_path = /disk1/ibdata1:10G;/disk2/ibdata2:10G;/disk3/ibdata3:10G:autoextend
In this example, the InnoDB tablespace is spread out over three physical disks -- perhaps because each disk has only 10 GB free, or maybe in an attempt to help spread out the I/O load. The third file is marked as autoextend, so that it can grow if needed.
Unfortunately, the attempt to balance the load across three disks does not work out very well in practice. InnoDB will fill the whole first data file before it starts using the second, and fill the second before it touches the third. Another problem comes from the database's inability to do online expansion of the tablespace. If you run out of space on disk #3 and have to add a file from some other device, you will have to shut down and restart the database server for the change to take effect. (You also have to do some clever bookkeeping with the auto-extend file, in this example, but that's a detail that's best skipped over in this discussion).
It could improve the situation to remove the complexity of storage management from the database realm altogether. Here is the only innodb_data_file_path that any ZFS system might ever need:
innodb_data_file_path = /dbzpool/data/ibdatafile:10G:autoextend
You can split this over as many drives as you want, and ZFS will balance the load intelligently. You can stripe it, mirror it, add space when you need room to grow, bring spare disks online, and take faulted disks offline, without ever restarting the database. You can let the database be the database, and – for us at MySQL – we can focus on keeping that database simple, inexpensive, and easy to use.
In MySQL's Falcon storage engine, tablespaces can be created and dropped online, but they can only contain one data file. Robin's primer on Falcon tablespaces tells us to "expect tablespaces to support multiple datafiles in future Falcon versions," but a ZFS user would never need that feature.
Filesystems, buffering, and read-ahead
Filesystem layers traditionally include a small set of features that provide a huge performance boost to most applications. First, they provide buffering -- an intermediate staging area in memory, between the physical disk and the applications using it. Secondly, they perform read-ahead: if an application asks for a large contiguous block of a file, the filesystem will read an even larger one, in anticipation that the application will keep reading forward.
A database server, in this regard, is not a typical application. Although there is one very unusual database, MyISAM, which relies on the file system buffer cache for caching of data rows, and thus is unaffected by the problem described in this section, most others provide their own layer of buffering. Database performance depends extensively on the effective use of that cache: every time there is a cache miss, and you have to physically read the data from the disk, performance goes down.
A problem shows up in when data is cached twice in memory -- once in the database server, and a second time in the filesystem. Storing two copies of the data effectively cuts the machine's RAM in half. When the memory is full, it only holds half as much data as it might, so there are more cache misses, more reads, and lower performance. This is what we will call the "double buffer problem."
The other optimization, read-ahead, can also be detrimental to a database server. The reads performed by a database do not fall into a predictable pattern, so the filesystem ends up pre-fetching data that never gets used. Roch Bourbonnais, a performance engineer and blogger at Sun, observes that when Sun's traditional UFS filesystem "sees access to 2 consecutive pages, it will read a full cluster, and those are typically 1MB in size today." The time that the disk head spends reading unneeded data could have been spent doing something more useful.
Most MySQL users, especially on Solaris, respond to these two problems simply by turning the features off. Accessing a filesystem without buffering and read-ahead is known as Direct I/O, and it can be enabled in my.cnf by setting innodb_flush_method to O_DIRECT:
innodb_flush_method = O_DIRECT
Before MySQL 5.0.42 and 5.1.18, in April of 2007, it was also necessary on Solaris to mount the UFS filesystem holding the data files with the forcedirectio option. Luckily, this is no longer true, and InnoDB can now use direct I/O for its data files without forcing every application to use direct I/O on the entire filesystem.
ZFS Design and the I/O Scheduler
When InnoDB runs on ZFS, the double buffer problem shows up clearly, and its effects are easily seen in the benchmarks below. As for read-ahead, though, earlier releases of ZFS suffered from a bad read-ahead effect, but current ones (since OpenSolaris Nevada build 70, at least) do not. Another Sun engineer and blogger, Neelakanth Nadgir, did some work benchmarking ZFS with databases in 2006, and noticed some performance problems that have been fixed in the newest builds.
ZFS introduces a third interesting performance enhancement, an I/O scheduler. The ZFS I/O scheduler works along this plan:
- When an I/O request comes into the kernel, it is put into a queue and assigned both a priority and a deadline. (The higher the priority, the sooner the deadline).
- Read requests get a higher priority than write requests, because reads are inherently synchronous (the application is blocked, waiting for them to return). Effectively, read requests get to jump to the front of the queue.
- The I/O scheduler gets to look at all of the pending requests and decide which one to run next. It does this by taking all of the requests in the most urgent "deadline group" and sweeping them across the disk in order of Logical Block Address.
To bring in yet another Sun blogger, there is at least one benchmark where the ZFS I/O scheduler has been shown to make a big difference in performance.
Deploying MySQL on ZFS: The Details
ZFS and MySQL look like a promising combination, but how do the details fit together? Often enough, a database server and a filesystem will acknowledge the same set of problems, and each offer a solution. The two solutions might fit together well or that might overlap badly. Here are a few important points.
Set the ZFS Recordsize to match the block size
ZFS tends to heuristically determine the block size for each file based on the file's total size and how it is used. Small files are managed in tiny chunks, and huge files are managed in large chunks. The ZFS designers knew that this scheme would optimize common cases, but that it could be wholly inappropriate for database servers, and therefore they allow a user to set a fixed record size when filesystems are used with a database. Some of the reasoning later in this article is only valid of the database page size and ZFS record size are equal.
InnoDB manages data files in 16KB pages, unless you recompile it to use a larger page size. Falcon uses a 4KB page size by default, but allows the size to be configured in my.cnf. In both cases, it's important that you set the ZFS recordsize to match the size of data pages. This needs to be set before creating any files on the volume, and the command to set it looks like this:
# zfs set recordsize=16K zp1/data
The InnoDB Doublewrite buffer and transactional storage
Some transactional systems – though not InnoDB – write complete data pages to the transaction log file. InnoDB, however, logs just the page number and the changed rows, so that in the critical moment when a user is waiting for a transaction to commit, InnoDB sends less data to the disk, and it can perform better. If those other databases crash, and then restart and perform a crash recovery using the logs, they can pull the complete logged data page out of the log file and write it in to the data file.
With InnoDB, crash recovery is not quite so simple. Only a little bit of information was logged, so the data page must to be correct on disk. And InnoDB tries to insure this using a special area of the data file called the doublewrite buffer which contains a second copy of recently-written pages. After a crash, there are two copies of every volatile page – one in the normal file, the other in doublewrite – and at least one of those copies should be intact. The doublewrite buffer is not needed on ZFS, and a small performance gain can be obtained by turning it off.
Above all, what InnoDB's doublewrite buffer guards against is partial writes: cases where the database sent a 16 KB page to the disk, but only 4 KB or 8 KB was actually written before the power failed. This is where transactional semantics come in - not from the database, but from the filesystem: ZFS guarantees that partial writes never happen.
To take a closer look at partial writes, let's imagine a particular disk block – block 82, say – that was being overwritten in a traditional unix filesystem when the power failed. When the system comes back up, the first part of block 82 contains partially-written new data, the next bit contains garbage data, and the end of the block contains old data that was never overwritten. If the block happens to hold an InnoDB data page, the end of the page also contains a checksum, which, on inspection, will fail to match the page contents.
In ZFS, before the power fails, when the database goes to overwrite block 82, something entirely different happens. Block 82 is never actually overwritten at all; instead, a completely new block is written, somewhere else. Even if the power fails in mid-write, block 82 is left intact. If the power stays on, a bit is flipped, somewhere, atomically, and the new block is mapped into the file – the current version of the file, anyway – in place of the old. (There might be snapshots of previous versions of the file that continue to map in the old block. This is what database folks would call multi-version concurrency control, but at the filesystem layer, and it's a feature that has been in FreeBSD, NetApp, and Veritas filesystems for many years.)
MySQL Performance Comparison: ZFS vs. UFS on Open Solaris
I performed two different benchmarks to compare UFS with ZFS on Solaris. The machine used for testing was an x86 desktop with 2 GB of RAM, running OpenSolaris Nevada build 74 and MySQL 5.0.50. The first benchmark is a single-threaded "utility" benchmark intended to represent common operations such as bulk insert and ALTER TABLE. This benchmark showed no significant or interesting differences between the two filesystems, though some individual operations were as much as 5% slower on ZFS than on UFS,
The second benchmark is more interesting. This test involves 6 client threads accessing a database of 3.2 GB, in a pattern of 85% SELECT queries, with the rest divided between INSERTs and UPDATEs. The 3.2 GB database is too large to fit in memory, so the test is I/O bound, but the test also simulates the "active set" behavior of many real applications: a particular subset of records (about 5% of the total) is queried more often than the rest.
This test is particularly sensitive to cache behavior; each test run has some amount of "warm-up time" to seed the cache, and test runs cannot be legitimately compared unless they have the same warm-up period. In order to reset a warm-up period to zero, it is sometimes necessary to unmount and remount a filesystem, so that its buffer cache is cleared.
| InnoDB Buffer Pool Size | UFS Direct I/O | ZFS |
|---|---|---|
| 100 MB | 36.84 | 96.21 |
| 250 MB | 45.70 | 80.69 |
| 350 MB | 50.68 | 102.75 |
| 500 MB | 57.32 | 94.99 |
| 700 MB | 61.92 | 85.95 |
| 1000 MB | 82.41 | 98.35 |
| 1200 MB | 95.01 | 88.98 |
| 1400 MB | 101.32 | 117.83 |
The tests with a 5-minute warmup show that database performance on UFS increases steadily as the buffer pool grows. On ZFS, however, these results seem erratic and non-linear. When the warmup period is increased to 10 minutes, a much clearer picture emerges.
| InnoDB Buffer Pool Size | UFS Direct I/O | ZFS |
|---|---|---|
| 100 MB | 35.71 | 179.18 |
| 250 MB | 44.25 | 154.26 |
| 350 MB | 50.60 | 110.14 |
| 500 MB | 57.10 | 93.29 |
| 700 MB | 66.57 | 101.35 |
| 1000 MB | 103.47 | 114.18 |
| 1200 MB | 168.66 | 156.04 |
| 1400 MB | 325.05 | 290.14 |
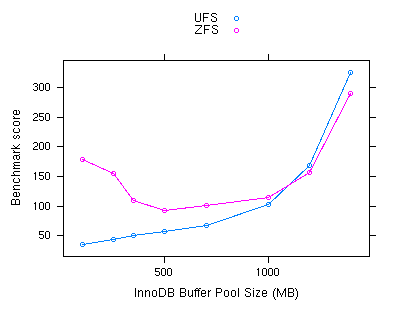
Again, performance on UFS increases steadily with a larger buffer pool, and then dramatically at the far end. The final two data points, at 1200 and 1400 MB, represent 60% and 70% of the machine's total available RAM, and are large enough to hold almost half the data set.
When the buffer pool is small, ZFS substantially outperforms UFS. The ZFS cache seems to be quite effective, as ZFS with a 100 MB buffer pool actually outperforms UFS with a buffer pool of 1200 MB. However, when the buffer pool gets larger, performance with ZFS goes down. This behavior is caused by the double-buffering problem. Since some data is in both caches, less of the total data set is in memory, and more physical disk access is required. This effect is at its worst when the buffer pool is set to 500 MB.
Beyond 500 MB, the two filesystems start performing in much more similar ways. The database server demands most of the physical memory, leaving very little left for ZFS, which both minimizes the ZFS contribution to performance and minimizes the double-buffer problem.
Conclusions
ZFS introduces remarkable ease and flexibility of administration, without any real cost in performance. At its worst, in these tests, ZFS performed almost as well as UFS with Direct I/O. With InnoDB, the ZFS performance curve suggests a new strategy of "set the buffer pool size low, and let ZFS handle the data buffering." I did not test Falcon, since it was not yet in Beta when I ran the benchmarks, but a similar strategy for Falcon on ZFS might be to concentrate on the row cache but minimize the page cache. And although double-buffering problems are clearly visible in this ZFS performance curve, even with those problems at their worst, ZFS still outperformed UFS. The real reason for the good performance on this benchmark is not clear -- indeed, every workload will be different -- but the ZFS I/O scheduler, the Sun engineers paying attention to database performance, and the ZFS bug fixes contributed in recent (late 2007) releases of Open Solaris seem to be adding up to something good.
Comments?
Read and post comments on this article in the MySQL Forums. There are currently 3 comments.