About the Author

Robin Schumacher is VP of Products at Calpont, which makes the analytic database, InfiniDB. Robin as over 20 years of database experience in MySQL, Oracle, SQL Server, Teradata, and other database engines. Before joining Calpont, Robin was Director of Product Management for MySQL/Sun.

Why Should I Check Out a MySQL-Based Column Database?
Some technologies come on the information technology landscape and stay, providing long-lasting benefits, whereas others are more of a short term fad and ultimately end up disappearing because the value they supplied was too niche oriented and/or they were quickly supplanted by another technology that is better. Recently, articles, blogs, analyst reports, and other media outlets have been noting the rise and usage of column-oriented databases in the areas of data warehousing, analytics, and other business intelligence/read-intensive situations. And on the MySQL front, there are a couple of column DB’s that are now available for you to use.
Are column-oriented databases a technology that is destined to stay and provide long-term benefits or will it be relegated to the forgotten pile of other software that came on the scene quickly and then disappeared?
Let’s look at three key questions that are consistently asked of column-oriented databases and see how the technology stacks up:
- How do column-oriented databases work?
- Do column-oriented databases really make a difference?
- What learning curve (application/database development, etc.) is involved with column-oriented databases?
How Do Column-Oriented Databases Work?
All the legacy relational databases currently being offered today were and are primarily designed to handle online transactional processing (OLTP) workloads. A transaction (e.g. an online order for a book through Amazon or another Web-based book dealer) typically maps to one or more rows in a relational database, and all traditional RDBMS designs are based on a per row paradigm. For transactional-based systems, this architecture is well-suited to handle the input of incoming data.
However, for applications that are very read intensive and selective in the information being requested, the OLTP database design isn’t a model that typically holds up well. Whereas transactions are row-based, most database queries are column-based. Inserting and deleting transactional data are well served by a row-based system, but selective queries that are only interested in a few columns of a table are handled much better by a column-oriented architecture. On average, a row-based system does 5-10x the physical I/O that a column-based database does to retrieve the same information. Taking into account that physical I/O is typically the slowest part of a query, and that an analytical query typically touches significantly more rows of data that a typical transactional database operation, the performance gap between row-oriented architectures and column-oriented architecture oftentimes widens as the database grows.
To get around their selective query inefficiencies, row-based RDBMS’s utilize indexing, horizontal partitioning, materialized views, summary tables, and parallel processing, all of which can provide benefits for intensive queries, but each comes with their own set of drawbacks as well. For example, while indexing can certainly help queries complete faster in some cases, they also require more storage, impede insert/update/delete and bulk load operations (because the indexes must be maintained as well as the underlying table), and can actually degrade performance when they become heavily fragmented. Moreover, in business intelligence/analytic environments, the ad-hoc nature of such scenarios makes it nearly impossible to predict which columns will need indexing, so tables end up either being over-indexed (which causes load and maintenance issues) or not properly indexed and so many queries end up running much slower than desired.
Those not familiar with a column-oriented database might wonder exactly what they are and what actual benefits they deliver over a legacy RDBMS. It’s important to note that, on the surface, a column-oriented database appears exactly like a traditional relational database: the logical concepts of tables and rows are the same, SQL commands are used to interact with the system, and most other RDBMS paradigms (e.g. security, backup/recovery, etc.) remain unchanged.
But, a column-oriented database specifically designed for analytics overcomes the query limitations that exist in traditional RDBMS systems by storing, managing, and querying data based on columns rather than rows. Because only the necessary columns in a query are accessed rather than entire rows, I/O activities as well as overall query response times can be reduced. In other words, if you don’t have to read an entire row to get the data you need, why do it?
The end result for column databases is the ability to interrogate and return query results against either moderate amounts of information (tens or hundreds of GB’s) or large amounts of data (1-n terabytes) in much less time that standard RDBMS systems can.
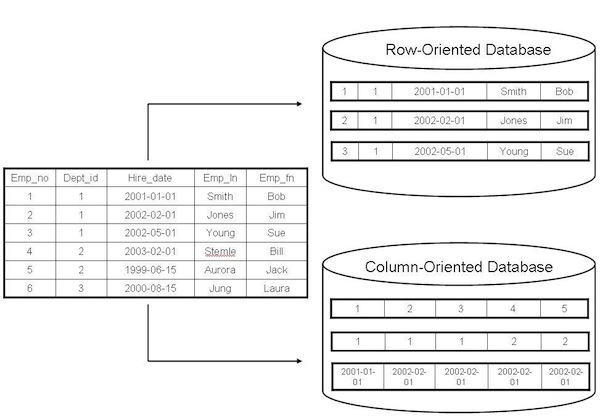
The good news for you who use MySQL is that the storage engine architecture allows column database vendors to plug their technology into MySQL and voila! You now have at your disposal a powerful alternative to other MySQL engines that can really tackle serious data needs.
Do Column-Oriented Databases Really Make a Difference?
So column databases look pretty good from a technical blueprint perspective, but do they really walk the talk in the real world? If they do, then their impact will be substantial because, in the end, the back end database used for BI or read-intensive work is the #1 overall contributor to a well running system.
The Data Warehouse Institute (TDWI) did a recent study and found that (not surprisingly…) the most important component in a business intelligence implementation was the database server itself.
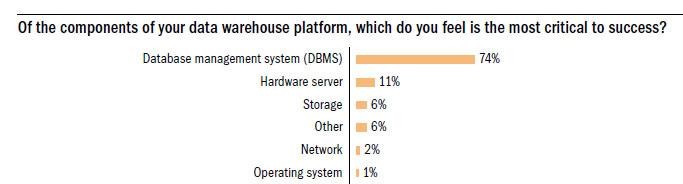
Further, TDWI found that nearly half of those it polled are ready to replace their database used for business intelligence applications with another, more modern alternative. When asked what the technical reasons were for the replacement, the number one answer was the inability for the legacy RDBMS to service queries in the time needed:
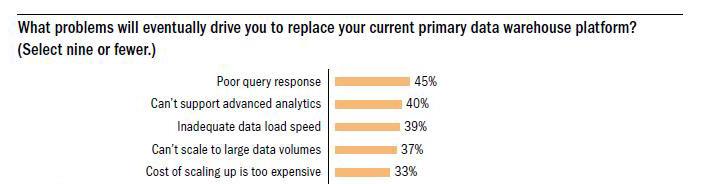
Interesting information, but do column databases really have the capability to help the pain these folks talk about?
As an example of how a column-oriented database can outperform a legacy RDBMS, Calpont recently commissioned a well-known data warehouse industry expert – Bert Scalzo – to benchmark a leading row-based database (of which he has many years of experience in tuning for fast performance) against Calpont’s InfiniDB Server (Community Edition), which has as one of its core features, a column-oriented design. A Star Schema styled benchmark was conducted on two different machines to gauge performance on both mid and large-sized servers. The mid-sized server was an 8 CPU, 8GB RAM, 14 SATA 7200 RAID-0 no cache configuration, and the large server was a 16 CPU, 16GB RAM, 14 SAS 15K RPM RAID-0 with 512MB cache machine. Both were running 64-bit CentOS 5.4. The raw database size was 2TB.
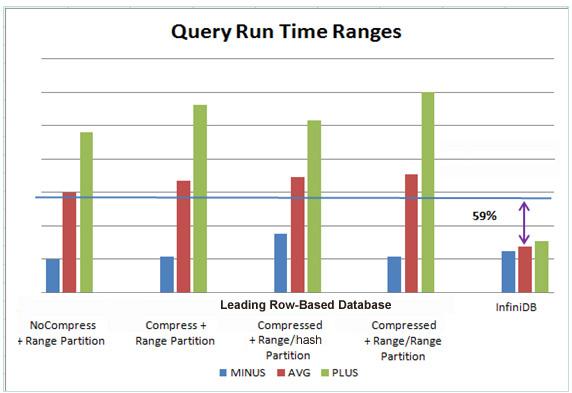
As can be seen on the graphs below, various configurations were used for the row-based database, however no matter the configuration, the column-oriented InfiniDB database consistently beat the legacy database in storage footprint, load time, and query speed:
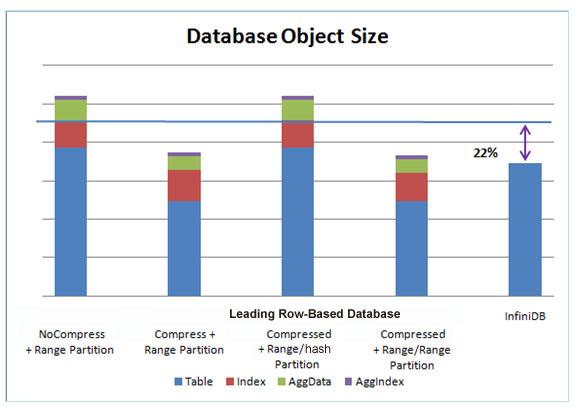
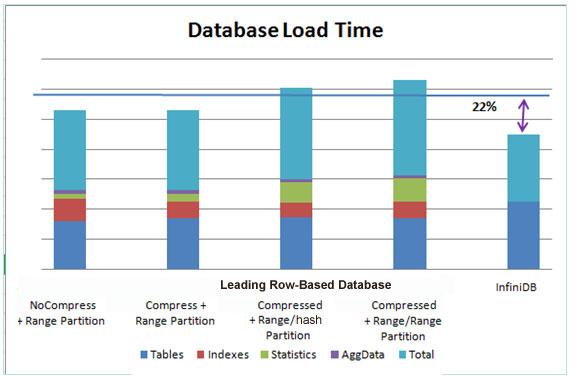
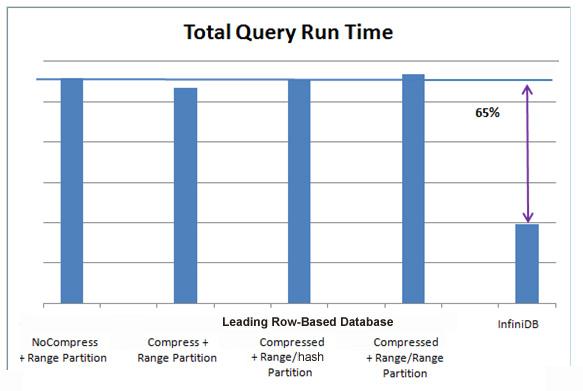
In summary, the column database saves on storage costs, supplies faster access to new/incoming data, and runs query much faster than its row-based competitor.
Notice also, that in addition to producing overall faster query speeds, InfiniDB also supplied much better query predictability in terms of query time. Whereas the row-based database produced wildly varying minimum and maximum query times over the various runs, the column database had a far more tightly group of runs when it came to predictable response times. This translates into much better dependability from a business standpoint in ensuring BI reports and queries meet whatever service-level agreements are imposed from business users.
Lastly, whereas the row-based database had been maxed out performance-wise in the benchmark tests, if a user wished to get even faster performance from InfiniDB, they could move from the Community Edition to the Enterprise Edition, which supports massive parallel processing (MPP) and shave the query times literally in half with the addition of a new node. Further, they could get their query time in half again by adding two more nodes (for a total of four) and continue to work in MPP fashion with more nodes until they reach whatever final query times they desire.
Additional Considerations
In addition to better performance, the column-orientation aspect of column databases supplies a number of useful benefits to those wishing to deploy fast business intelligence databases.
First, there is no need for indexing as with traditional row-based databases. The elimination of indexing means: (1) less overall storage is consumed in column databases because indexes in legacy RDBMS’s often balloon the storage cost of a database to double or more the initial data size; (2) data load speed is increased because no indexes need to be maintained; (3) ad-hoc DML work speed is increased because no index updates are performed; (4) no indexing design or tuning work is imposed on the database IT staff.
Second, there is far less design work forced on database architects when column databases are used. The need for complicated partitioning schemes, materialized view or summary table designs, and other such work is completely removed because column databases need none of these components to achieve superior query performance.
What Learning Curve is involved with Column-Oriented Databases?
You’ll be pleased to find that the learning curve associated with moving from legacy, row-based RDBMS’s to a column database is very small if not completely non-existent. Unlike other databases that came on the scene in prior years which required either different programming paradigms (e.g. object-oriented databases) or learning new design methodologies and database access languages (e.g. OLAP databases), column databases look and handle just like standard relational databases. They use the same ANSI standard SQL language, security methods, and require no development paradigm changes.
In fact, column databases actually lessen the burden on both the development and administration staff because they do away with the need for indexing exercises, data partitioning schemes, supplementary object designs (e.g. materialized views), and other similar tasks. The ease of use factor, therefore, is greater with column databases than it is with traditional RDBMS’s. Moreover, they do not require such specialized in-house expertise to build highly-performant systems.
Conclusions
In the end, the answer as to why you should consider a column database over a legacy RDBMS comes down to the fact that column databases do indeed make a big impact in how data warehouses, BI databases, and read-intensive systems perform. This makes column databases a good choice for today as well as a technology whose benefits will extend many years down the road.
To download the Community Edition of InfiniDB that uses MySQL as its front end, as well as free documentation, go to http://www.infinidb.org/downloads. To obtain a trial of InfiniDB Enterprise, please visit: http://www.calpont.com/.