About the Author

Yoshinori Matsunobu is a Senior Consultant at Sun Microsystems/MySQL, mainly engaging into consulting services in Japan and Asian countries. He wrote five MySQL books and one Java book(all of them written in Japanese), having broad-ranging MySQL technical experties, especially database administration, performance tuning, i18n and MySQL Cluster.

Falcon storage engine in depth
MySQL/Sun released a new storage engine "Falcon" in January, 2007. Falcon is a high performance transactional (fully compliant with ACID) storage engine, which is beta at this time (June 2008). In this article, I describe Falcon's features and its architecture in detail.
Falcon overview
Falcon was originally created by Jim Starkey who was inventor of MVCC, Blob's, Interbase, major Firebird contributor and his wife Ann Harrison.
The most basic feature covered by Falcon is transactions. Falcon supports commit/rollback, row-level concurrency through MVCC, non-blocking read and crash recovery. These are fundamental features for most enterprise applications.
In MySQL 5.0 and 5.1, the InnoDB and NDB (MySQL Cluster) engines support transactions. NDB is used for applications that want to easily achieve both high availability (99.999%: 5minutes downtime/year) and high performance (over 10 thousands TPS) easily. InnoDB is mainly adopted by single MySQL server or master/slave replication environment, like MyISAM. Falcon primarily targets the same use cases as InnoDB. That's why Falcon is expected to be an alternative to InnoDB. By using Heartbeat (or other clustering software) and DRBD/SAN, InnoDB or Falcon can achieve 99.99% level availability. If you want to achieve 99.999%, we usually recommend NDB (Note that NDB is not a drop-in replacement for InnoDB/Falcon. Use cases are different).
Falcon's internal architecture is quite different from InnoDB and some features are covered only with InnoDB. So please do not regard Falcon as a drop-in replacement for InnoDB (however, many of features do overlap). For example, the following features are covered with InnoDB, but not covered with Falcon.
Falcon doesn't use Clustered Index
Falcon doesn't use clustered index architecture. Clustered index has both pros and cons against general B+Tree index, mainly from a performance perspective.
Falcon does not support Read Uncommitted isolation level
Read Uncommitted, sometimes referred to as "dirty" reads, is not needed for most situations.
Falcon does not support Statement based replication
Starting from MySQL 5.1, both statement based and row based replication are supported for binary logging. Falcon supports only row based replication. This is to guarantee consistent result between binary log and data files.
Online backup will be supported by Falcon GA, but server-enforced referential integrity will not be exposed until MySQL 6.1. Falcon GA is planned to be released in MySQL 6.0.
Using Falcon
You can download MySQL binaries including Falcon from MySQL AB website. You can download Falcon source code, too.
http://dev.mysql.com/downloads/mysql/6.0.html
The procedure of installation is the same as previous versions (5.1/5.0/4.1 or less). You can install by rpm , extracting tar.gz, or building from source.
To check that Falcon is installed, run the "SHOW ENGINES" statement. If there is an item of "Engine: Falcon" and "Support: YES", Falcon can be used.
mysql> SHOW ENGINES \G (snip) *************************** 3. row *************************** Engine: MyISAM Support: YES Comment: Default engine as of MySQL 3.23 with great performance Transactions: NO XA: NO Savepoints: NO *************************** 4. row *************************** Engine: Falcon Support: DEFAULT Comment: Falcon storage engine Transactions: YES XA: NO Savepoints: YES *************************** 5. row *************************** Engine: MRG_MYISAM Support: YES Comment: Collection of identical MyISAM tables Transactions: NO XA: NO Savepoints: NO *************************** 6. row *************************** Engine: InnoDB Support: YES Comment: Supports transactions, row-level locking, and foreign keys Transactions: YES XA: YES Savepoints: YES (snip)
To create a Falcon table, just add "ENGINE=Falcon" in CREATE TABLE or ALTER TABLE statement. This is the same with creating other types of tables.
mysql> CREATE TABLE tbl1 (id INTEGER AUTO_INCREMENT PRIMARY KEY, value VARCHAR(30)) ENGINE=Falcon;
mysql> SHOW CREATE TABLE tbl1\G
*************************** 1. row ***************************
Table: tbl1
Create Table: CREATE TABLE 'tbl1' (
'id' int(11) NOT NULL AUTO_INCREMENT,
'value' varchar(30) DEFAULT NULL,
PRIMARY KEY ('id')
) ENGINE=Falcon DEFAULT CHARSET=latin1
When the ENGINE clause is omitted, it automatically becomes a Falcon table if "default-storage-engine=Falcon" is specified in the database configuration file my.cnf.
Transactions are also supported:
mysql> START TRANSACTION; mysql> INSERT INTO tbl1 VALUES(null,'abc'); mysql> ROLLBACK; mysql> SELECT * FROM tbl1; Empty set (0.00 sec)
The result set is empty because the INSERT is rollbacked.
As you see, because Falcon is just one of the storage engines in MySQL, the SQL syntax is not different from other storage engines. You are likely much more interested in Falcon's internal architecture than in SQL syntax, so I will now delve into the following technical topics:
- Process/Thread and Memory model
- File structure
- Index and record retrieval
- Data type and space management
- Transaction
Process/Thread and Memory model
MySQL is a single-process (mysqld), multi-threaded RDBMS. Per each connection, mysqld allocates one dedicated thread. There are also some utility threads such as accepting connections (listener thread), and one accepting signals. Some storage engines have their own threads. Falcon has its own threads that are used for tasks such as running checkpoints and doing garbage collections. These threads run in the background. InnoDB also has similar threads.
To improve thread concurrency, Falcon does not use mutexes directly, but uses mutex-wrapper objects called "SyncObjects". SyncObjects enables read/write locking. So many threads can read shareable structures at the same time. This is a very important feature for multi-cpu core environment.
Falcon's memory structure is shown as Fig.1. Falcon has four major dedicated memory areas called Record Cache, Page Cache, Log Cache and System Cache.
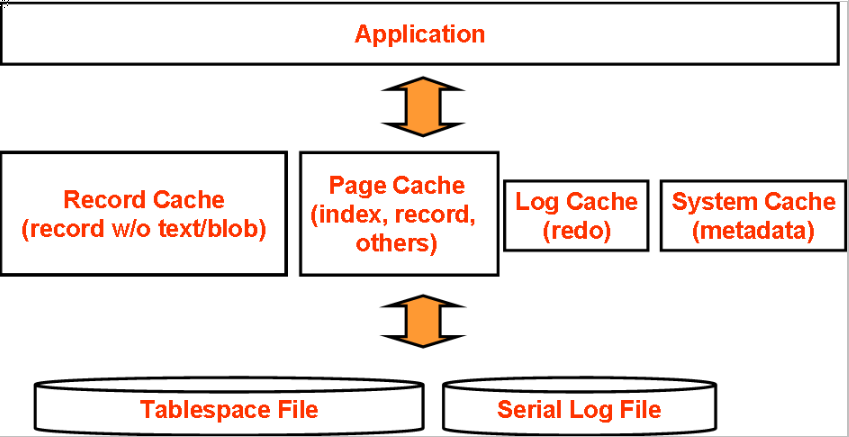
Fig1. Falcon Memory architecture
The Record cache exists to cache individual records with almost no overhead. Further, the Record cache does not hold TEXT/BLOB (except TINYTEXT/TINYBLOB) column values. So, the Record cache enables the caching of many more records than a Page-type cache. Also, with the Record cache, selecting records is faster. The record cache holds more *useful* record data than a page cache, such as newer and older record versions needed for MVCC.
The Page cache is similar to the InnoDB buffer pool where information from the data files are cached. Falcon's page size is configurable (2KB,4KB,8KB,16KB,32KB is currently supported) though the InnoDB page size is fixed to 16KB. Page size tuning sometimes improves performance greatly.
The Log Buffer is used to keep uncommitted transactional records, which is similar to InnoDB's Log Buffer.
The System cache is used to cache metadata objects.
File structure
Falcon's storage management consists of two kinds of files: tablespace files and log files.
A tablespace file contains all record data, indexes, database metadata and other information. This is similar to a InnoDB data file. Falcon also supports "CREATE TABLESPACE" syntax. Please refer to Robin Schumacher's article for details.
A log file in Falcon is called the Serial log file, and it contains transactional (redo) information. All committed records are synchronously written to the Serial log file. This is quite similar to InnoDB. However, the size of Serial log files is not constant while the size is fixed in the InnoDB log file.
To guarantee durability, RDBMS needs to synchronously write to a transaction log file when transaction commits. This often causes performance problems. Falcon reduces the number of disk flushes by its "Group Commit" feature. When two or more transactions commit at the same time, Falcon sums up them and synchronously writes at one time. Falcon automatically recovers from a crash by using a Falcon tablespace file and a Serial log file.
Many RDBMS support "Checkpoint" technology, which writes both committed and uncommitted data into both data files and redo log files. Falcon writes uncommitted data only to its Serial log file. After committing transactions, committed records are transferred to the data page in the Page Cache by the gopher thread. If the transaction is rolled back, uncommitted records are not transferred, just truncated. So the cost of rollback is very cheap for Falcon.
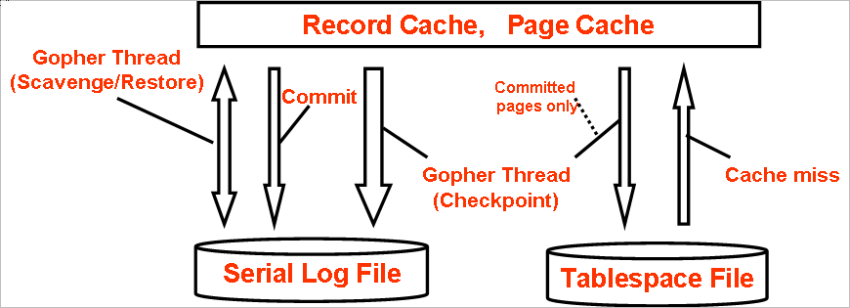
Fig2. How Falcon Files are read/written
Index and record retrieval
The Falcon index structure is completely different from InnoDB. InnoDB uses a clustered index architecture. Clustered index contains the whole column values referenced by a primary key. When selecting records from secondary index, InnoDB has to lookup a primary key by a secondary index in the first step, then lookup the whole record by its clustered index (primary key) in the second step. By using a Clustered Index, primary key search is very fast. But secondary key search is slower than a general B-Tree index.
Falcon doesn't use clustered index. A Falcon index is an improved B-Tree index, and contains an index key value in leaf, pointing to an internal unique record number (Fig.3).
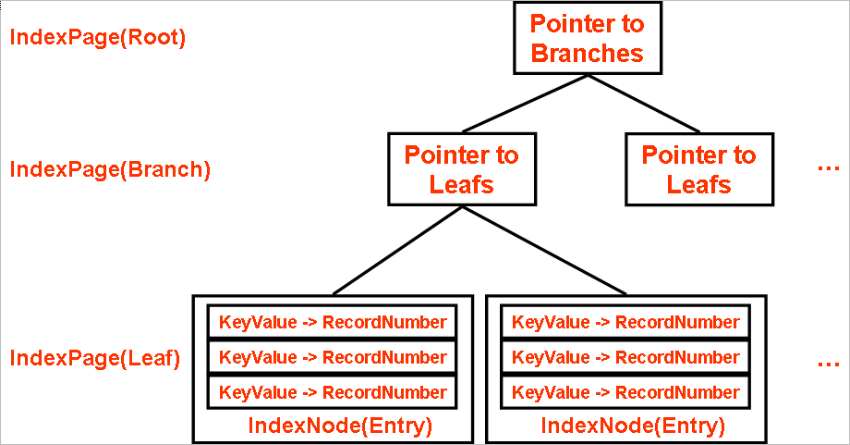
Fig3. Falcon Index Structure
A Record number is an internal unique identifier to the target record. Falcon looks up records from the Record Cache by record number (Fig.4). If the record is not cached, Falcon looks up data pages in tablespace files.
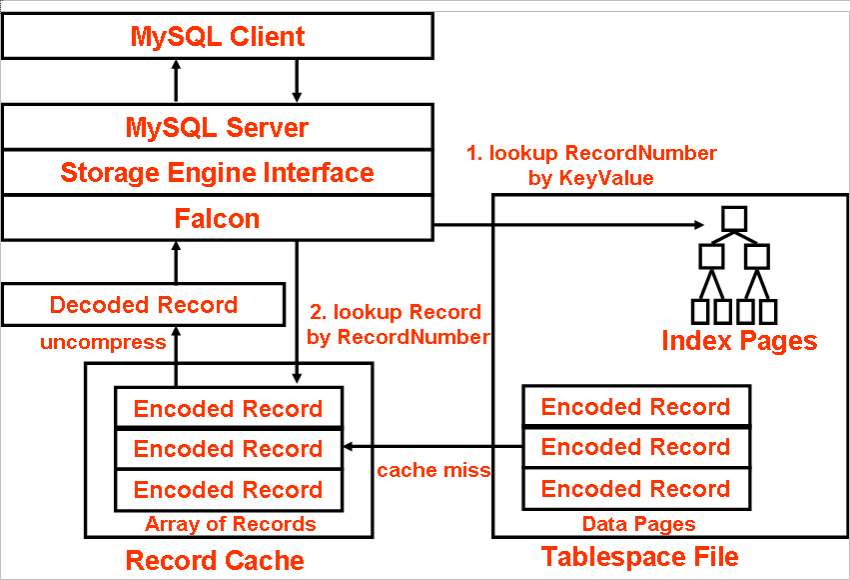
Fig4. How Falcon looks up records
Some DDL statements such as ALTER TABLE, CREATE INDEX are also faster. MySQL AB is now working on performance improvements for Falcon, so some benchmarks will be shown in the near future.
Index search by storage order
When selecting records by using an index, Falcon first lists up record numbers of all targeted records, storing them into internal bitmap, then scans the index by record number order. Since record number order is equivalent to storage order, it can reduce disk seek time. This is especially effective for range scan such as BETWEEN, >=, <= .
Index compression
Falcon indexes also have prefix and suffix compression to reduce I/O load. Suffix compression for numbers truncates trailing zeros. Suffix compression for strings truncates trailing spaces.
Prefix compression is an interesting feature of Falcon. The first index in each page of index entries has no prefix compression. The next index starts with one or two bytes indicating the number of leading bytes that are exactly the same as the leading bytes of the previous index (Fig5).
Multi-column index compression logic is more complex, but reduces index sizes similarly.

Fig5. Falcon's index compression
Index accelerator
Falcon implements an "Index accelerator" to speed up inserting/updating/deleting many records within transactions.
To reduce the cost of adding lots of index entries, Falcon implements in-memory index accelerators that buffer index changes in memory until a commit. Because all the index changes made by a transaction are applied in sorted order, Falcon avoids making scattered changes throughout the index. Adding a single large block to the serial log is also faster than adding numerous small blocks. Index accelerators improve the performance of bulk loads and mass updates or inserts on existing tables.
Data types and space management
Falcon supports all MySQL data types including GIS type.
Falcon handles all data types as variable length. For example, INTEGER is always 4 bytes for MyISAM. But for Falcon, it depends on the actual value. If value is 100, Falcon consumes only 1 byte for actual value (plus 1 byte to handle data type and 1 byte to handle length, these are common to handle to variable length columns) even though the type may be BIGINT.
TEXT/BLOB Optimization
Falcon can also handle TEXT/BLOB types efficiently. TEXT/BLOB values are stored in a different area (page) from other type values. This can avoid fragmentation. In general, BLOB values tend to be much larger than other types. Frequent update/delete of large columns often causes fragmentation of data files. Since Falcon manages TEXT/BLOB values at different pages from other values, such fragmentations don't happen.
Another strong point is that Falcon doesn't retrieve TEXT/BLOB values unless it is needed. Let me show a simple example at Fig.6. The diary table has two BIGINT, DATETIME, VARCHAR and TEXT columns. The diary_text column is much larger (over thousands bytes) than other columns. Suppose most of queries retrieve only user_id, date_added and title, which don't need diary_text. In such cases, Falcon can use memory much more efficiently because Record Cache doesn't have TEXT/BLOB column values. TEXT/BLOB column values are stored in separated data pages. So each record size cached in Record Cache is small, that's why Record Cache can cache many records regardless of BLOB/TEXT values.
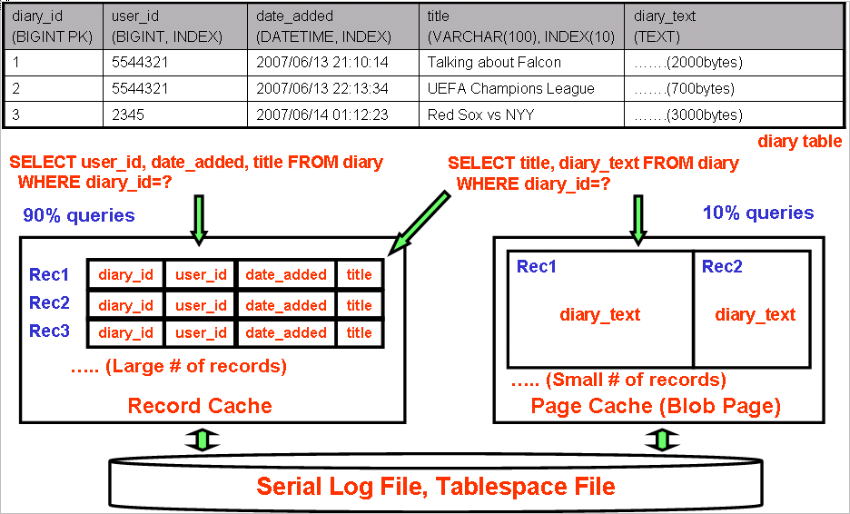
Fig6. Falcon TEXT/BLOB optimization
InnoDB is different from Falcon as shown at Fig.7. All columns are cached into the InnoDB Buffer Pool even though diary_text column is not needed. So in this case, Falcon Record Cache can contain much more records in cache than InnoDB Buffer Pool, which can reduce frequent page-in/out activity significantly. Frequent page in/out often causes serious performance impact. This is one of the biggest advantages of Falcon.

Fig7. InnoDB BLOB/TEXT
Moreover, records are not physically reallocated unless really needed. Reallocating records result in a lot of disk I/Os and Falcon takes care of reducing such I/Os.
AUTO_INCREMENT
AUTO_INCREMENT(sequence) column behavior is different between Falcon and InnoDB. After rebooting mysqld, the next AUTO_INCREMENT value is the following:
- InnoDB: SELECT MAX(auto_increment_column) + 1
- Falcon: Maximum value +1 that has been inserted up to now (same as MyISAM)
This behavior can be demonstrated in the following example:
mysql> CREATE TABLE tbl1(id INT AUTO_INCREMENT PRIMARY KEY); mysql> INSERT INTO tbl1(id) VALUES(null); mysql> INSERT INTO tbl1(id) VALUES(null); mysql> INSERT INTO tbl1(id) VALUES(null); mysql> INSERT INTO tbl1(id) VALUES(100); mysql> DELETE FROM tbl1 WHERE id=100; mysql> SELECT id FROM tbl1; | id | | 1 | | 2 | | 3 |
Then reboot mysqld, running the following query:
mysql> INSERT INTO tbl1(id) VALUES(null);
The result is different between Falcon and InnoDB.
Falcon, MyISAM:
mysql> SELECT id FROM tbl1; | id | | 1 | | 2 | | 3 | | 101 |
InnoDB:
mysql> SELECT id FROM tbl1; | id | | 1 | | 2 | | 3 | | 4 |
For almost all cases, Falcon's behavior will be widely accepted.
Transaction Control (MVCC and exclusive control)
As said before, Falcon supports transactions. Not only COMMIT/ROLLBACK but also the SAVEPOINT statement is supported. When a SQL statement error occurred during transaction, only the executing statement since the last SAVEPOINT is rolled back. The transaction is still running. This is the same as InnoDB.
Let's dig down a little more about other transaction functionalities.
Falcon supports Multi Version Concurrency Control(MVCC)
MVCC enables the selection of committed rows without locking. So a select doesn't conflict with an update or other DML. This is extremely important functionality from a performance perspective.
Locking reads (SELECT FOR UPDATE) is also supported.
Transaction isolation level
Read Committed and Repeatable Read are supported. Serializable will be supported after GA. Read Uncommitted is not planned to be supported because it is not needed for most cases.
The ANSI/SQL specification specifies that Repeatable Read causes phantom read, but Falcon's Repeatable Read can avoid it. This is the same as InnoDB.
Falcon avoids Lock Escalation
When the number of records locked increases, some RDBMS escalates the lock level from row level to page or table level to save row management overhead. This is called "Lock Escalation". Lock Escalation is a problem because it decreases concurrent performance significantly. Falcon never causes lock escalation. InnoDB also never causes lock escalation, either.
Deadlock detection
Falcon automatically detects deadlocks. InnoDB also supports deadlock detection.
You might think that Falcon's transaction features are almost the same as InnoDB, but there are some differences.
Automatic detection of Lost Update (optional)
When multiple transactions update the same record at the same time, the last transaction updates all previous transactions' result. This is called "Lost Update". See the following example.
mysql> CREATE TABLE tbl2 (id INTEGER AUTO_INCREMENT PRIMARY KEY, value INTEGER) ENGINE=Falcon; mysql> INSERT INTO tbl2 VALUES(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10);
| Transaction 1 | Transaction 2 | |
| 1) | START TRANSACTION; | START TRANSACTION; |
| 2) | SELECT value FROM tbl2 WHERE id=1; # returns 1 | |
| 3) | UPDATE tbl2 SET value=100 WHERE id=1; | |
| 4) | SELECT value FROM tbl2 WHERE id=1; # returns 1 | |
| 5) | UPDATE tbl2 SET value=10 WHERE id=1; (Innodb and Falcon running with "Innodb compatible" transactions make transaction 2 wait for transaction 1 to commit. Falcon's natural Repeatable Read Isolation mode will return an update conflict at 6). | |
| 6) | COMMIT; | |
| 7) | COMMIT; |
The final value is 10 if InnoDB is being used. This is because transaction 1 is implicitly updated by transaction 2. This is a typical situation of "Lost Update".
Falcon's natural Repeatable Read isolation does not allow Lost Update situation. Falcon's natural Repeatable Read returns error at 6) as below. The final value is 100. If multiple transactions update the same record at the same time, Falcon commits the first record, then does a rollback on all conflicting transactions at the time the first transaction is committed.
mysql> UPDATE tbl2 SET value=value+10 WHERE id=1; # 6) ERROR 1020 (HY000): Record has changed since last read in table 'tbl2'
Falcon's natural Repeatable Read checks the row version to check if the record is changed by other transactions after starting the transaction. If the row version is updated, the latter transaction must be rolled back when the error is received. This guarantees former-win model. This is good, because Lost Update is not acceptable for many applications. SELECT FOR UPDATE is a well known workaround. SELECT FOR UPDATE blocks transaction 2 at 4) until transaction 1 is committed.
Falcon also supports "InnoDB Compatibility Mode" currently (beta release) in order to improve the throughput of concurrent transactions. For beta, Falcon will only provide repeatable read transaction in "InnoDB compatibility mode". For GA, there will be the ability to choose between the two.
If an application transaction is divided into multiple transactions (e.g Web application: one transaction to select employee info, another transaction to update it ), the Falcon former-win model doesn't work. In this case, adding a version control column is the best for many cases. This is also a well-known solution.
Avoiding next-key locking
InnoDB locks not only updated records, but also locks next to records. This is called "next-key locking". Next-key locking is needed to guarantee consistency of statement-based binary logging in InnoDB. Falcon locks only updated records. So lock extent is decreased. But please note that Falcon doesn't support statement based binary logging, only row based binary logging. In MySQL 5.1, if row-based binary logging is enabled and the READ COMMITTED isolation level is used, there is no InnoDB gap locking except in foreign key constraint checking.
Conclusion
In this article, I explained the Falcon architecture, mainly comparing it with InnoDB. The falcon team is now mainly working on bug fixing and performance improvements for the next releases of the Falcon. Performance benchmarking results will be posted in the near future.