About the Author

Robin Schumacher is MySQL's Director of Product Management and has over 13 years of database experience in DB2, MySQL, Oracle, SQL Server and other database engines. Before joining MySQL, Robin was Vice President of Product Management at Embarcadero Technologies.

Data Warehousing with MySQL and Infobright
Unless you’ve been on a desert island lately, you probably know that the area of data warehousing/analytics/business intelligence (BI) is going gangbusters these days. Not many years ago, when industry analyst groups polled CIO’s on their top priorities, BI was #10. Then it jumped to #2 in 2006, and today it’s #1 according to Gartner group. It’s no mystery as to why this is: it’s a cut-throat economy out there in all industries and smart businesses need to tap their internal data to make critical business decisions, both tactically and strategically, to stay ahead of the pack.
But here’s the rub: putting together a major BI landscape in a company can cost some serious cash. The better-bring-your-AMEX-goldcard attitude of a lot of data warehousing and BI vendors has caused some frustration on the part of many IT directors; in fact, a 2007 InformationWeek survey found that 39% of IT executives complained that software licensing costs prohibited them from rolling out the BI initiatives they want.
But enter open source! Just as open source has revolutionized many areas of software these days and opened the doors for nearly any company to craft a competitive IT environment of operating systems, development tools, and databases, it’s now doing the same thing in the area of data warehousing and BI. Witness the fact that data warehousing (as indicated on MySQL’s last major community and customer poll) is now the fifth most common use case for MySQL.
But here’s another statistic to digest: according to TDWI, the average growth rate of data warehouses ranges between 33 and 50% per year, and that’s conservative for some businesses. The most popular storage engine used for MySQL data warehousing today is MyISAM (second is InnoDB), and it does just fine performance-wise up to around 1TB of data. After that, a lot of users tend to partition their data warehouse across more than one server to help performance. Now, stats from the analyst group IDC say that the majority of data warehouses are 6TB and under (only 4% are over 25TB according to IDC), so that means most folks these days are looking to manage warehouses between hundreds of GB and 6TB.
If this is you, and you want to stay with a MySQL-based solution, then you owe it to yourself to check out the Infobright storage engine. Infobright, one of MySQL/Sun’s partners, supplies an engine that breaks through the limitations of MyISAM and other storage engines and delivers a very sophisticated piece of technology that (surprisingly…) doesn’t require heavy lifting when it comes to install, setup, and database design to get incredibly fast response times.
Let’s first take a look at the Infobright architecture to see how it accomplishes these things and then take it for a test drive to see how well it really performs on analytic-styled queries.
Columns are Cool
In a nutshell, the Infobright storage engine is a column-oriented architecture that combines a high-speed data loader, strong levels of data compression, and a smart, external optimizer and ‘knowledge grid’ to deliver impressive data warehousing capabilities. From a MySQL standpoint, Infobright presents just as any other storage engine would so there’s nothing really new to understand from an interface standpoint. Infobright is a separate install, however, from the general MySQL server, but it installs very simply (actually faster than a standard MySQL install I found), and is only a 17MB download, which is pretty remarkable for an engine that can scale up to managing ten’s of terabytes.
The first thing to note is that the Infobright engine is a column-oriented design. Column-oriented databases have been around for a while now (e.g. Sybase IQ), but are now coming on strong in popularity due to their strength in servicing data warehouse needs. In his March 2008 research report “What’s Cool About Columns”, Philip Howard of Bloor Research writes, “For much of the last decade the use of column-based approaches has been very much a niche activity. However … we believe that it is time for columns to step out of the shadows to become a major force in the data warehouse and associated markets.” He then adds, “Columns provide better performance at a lower cost with a smaller footprint: it is difficult to understand why any company seriously interested in query performance would not consider a column-based solution.”
Why would he make such statements? Because column-oriented designs like Infobright really do pack quite a punch in data warehousing situations. There are numerous reasons for this being the case, but here are just a few. Most data warehousing/analytic queries are only interested in a couple of columns in one or more tables rather than entire rows of columns. This being the case, storing data in the typical row-based format is inefficient for data warehouse purposes whereas storing data in a column-oriented fashion is much better. In a column-oriented design like Infobright, full table scans will never be performed (unless a query requests all or the majority of rows in a table); only full column scans may be. The end result is much less I/O and improved response times for column-oriented databases.
Infobright combines a column-oriented design with something else that everyone should like: high-levels of data compression. Because it’s column-oriented, when Infobright compresses data, it does so for each column, which is normally more efficient than standard row-based compression because the compression algorithms can be finely tuned for each column datatype. In normal row-based compression, you do well to see 2 or 3-to-1 compression; with Infobright, 10-to-1 compression is the norm (with some cases going much higher), so a 1TB database can be compressed down to 100GB. When some of the members of the Sun performance team saw this in action, they remarked to me how surprised they were at how well Infobright compressed data vs. many of the other databases (row-based and column-based) they had worked with. Of course, another by-product of compression is that not only does it help on the performance side, but it also helps on the storage cost side of the house, which should please most IT managers.
Other Infobright Technical Benefits
Although you can load data into a MySQL Infobright table via all the standard routes, Infobright also provides a special high-speed loader that really makes a difference in pumping data into a database. The loading algorithm is multi-threaded, which allows each column to be loaded in parallel. Single table loads with the Enterprise edition of Infobright run typically around 100GB an hour and multi-table loads can accomplish nearly 300GB an hour for binary data, which isn’t too shabby. The Community edition of Infobright has slower load speeds as it only handles text-based input (as opposed to binary), but you’ll still see loads around 40GB or so an hour.
But perhaps the major technical star in the Infobright architecture is its “knowledge grid” and accompanying optimizer. Infobright begins construction of the knowledge grid at the time data is loaded into the database (either initially or incrementally). The knowledge grid is essentially a statistical description of the data and demographics in the database. Here’s a key thing to remember about the knowledge grid: it serves as a substitute for indexes, which means you never create an index on an Infobright table. Never. And this is a good thing!
The Infobright knowledge grid does not have the maintenance disadvantages of indexes, which as we all know, cause insert and update response times to degrade over time as more and more modifications are made to a database. Another advantage is that Infobright does extremely well at servicing unpredictable queries, which are exactly what many data warehouses have to deal with. Such queries are a DBA’s nightmare because they can never design an efficient indexing or partitioning strategy, and performance is never that great. But with Infobright, such problems evaporate because it does all the work dynamically for you.
The actual data in Infobright is stored as columns as previously mentioned. The columns themselves are divided into groups of 64K values called data packs, whose metadata is stored in the knowledge grid. When a query is submitted to Infobright for execution, the optimizer consults the knowledge grid in order to generate a rough idea of which data packs contain data needed for the result set of the query. Queries run exceptionally fast when (a) there are relatively few data packs containing data in the result set, and (b) the optimizer is able to accurately identify the set of needed data packs.
One way to think of this data distribution is something akin to auto data partitioning. And again, this is a good thing. With Infobright, you don’t have to be a data warehouse design god to get an exceptionally performing data warehouse as it does nearly all the hard work for you – no indexing or partitioning strategies are necessary on your part.
In some cases a query can be executed without looking at any data packs at all; only the knowledge grid is consulted, and such queries will execute instantaneously. Since the knowledge grid contains many aggregate values, and because aggregates are a common aspect of queries in data warehousing applications, it is not unusual for many data warehousing type queries to execute with little or no required processing (examples follow below).
Application scenarios where Infobright tends to shine are star schemas (although true star design isn’t required) with deep, wide fact tables and shallow dimension tables, and designs where the tables in the databases are largely denormalized. Use cases where Infobright may not perform as well include applications with highly normalized schemas and more random data distributions. This is because such data doesn't compress as well as data with clustered patterns and because the data in the query result sets are spread around the database so that large numbers of data packs need to be scanned.
So enough talk – let’s now exercise the Infobright engine across some standard data warehouse use cases and see how well it does. All the tests below were executed on a Dell PowerEdge 6850, with four Intel Xeon dual-core processors (3.4 GHz), 32GB of RAM, and five 300GB internal drives configured in RAID 10 style, running on 64-bit Red Hat Enterprise Linux 5 with Infobright Enterprise edition.
Kicking the Tires
Working with Infobright is pretty much the same as any other MySQL engine when it comes to creating tables – all you do is specify brighthouse as the engine type. For example:
mysql> create table t (c1 int) engine=brighthouse; Query OK, 0 rows affected (0.02 sec) mysql> insert into t values (1), (2), (3); Query OK, 3 rows affected (0.16 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> select * from t; +------+ | c1 | +------+ | 1 | | 2 | | 3 | +------+ 3 rows in set (0.00 sec)
So now onto the actual tests: the schema I used for the queries below was a standard data warehousing star schema (representing a car sales database) that can be depicted in a data model as follows:
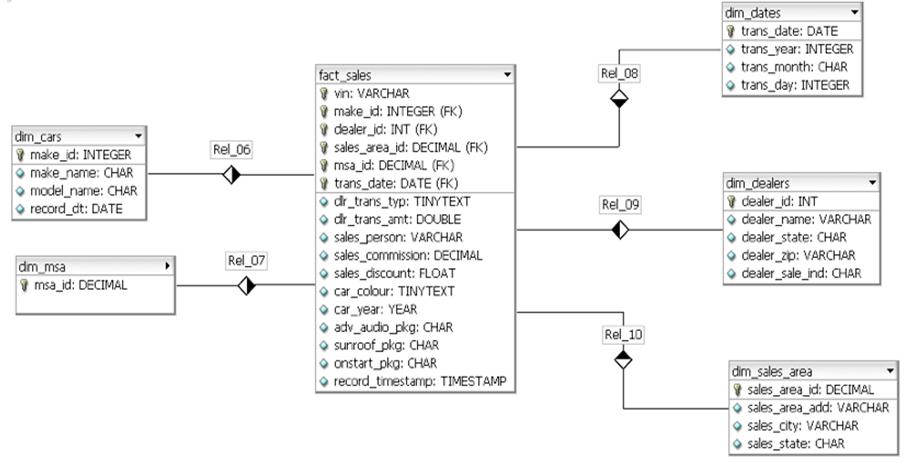
The number of rows and overall size of the database (as calculated from the information_schema) is as follows:
+----------------------------+-------------+------------+--------------+ | table_name | engine | table_rows | data_length | +----------------------------+-------------+------------+--------------+ | fact_sales5 | BRIGHTHOUSE | 8080000000 | 135581094511 | | fact_sales | BRIGHTHOUSE | 1000000000 | 16789624027 | | fact_sales1b | BRIGHTHOUSE | 1000000000 | 17424704919 | | mthly_sales_by_dealer_make | BRIGHTHOUSE | 4207788 | 43958330 | | dim_vins | BRIGHTHOUSE | 2800013 | 15251819 | | dim_sales_area | BRIGHTHOUSE | 32765 | 302326 | | dim_dates | BRIGHTHOUSE | 4017 | 9511 | | dim_dealers | BRIGHTHOUSE | 1000 | 9631 | | dim_dealers2 | BRIGHTHOUSE | 1000 | 10222 | | dim_cars | BRIGHTHOUSE | 400 | 4672 | | dim_msa | BRIGHTHOUSE | 371 | 3527 | | tt | BRIGHTHOUSE | 1 | 193 | +----------------------------+-------------+------------+--------------+ 12 rows in set (0.00 sec) +------------------+ | sum(data_length) | +------------------+ | 169854973688 | +------------------+ 1 row in set (0.01 sec)
The above shows a couple of fairly big fact tables at 1 billion rows each, a larger historical fact table at a little over 8 billion rows, one medium-sized summary table (4 million rows), and a number of dimension tables that are fairly small in size (except the 2.8 million row dim_vins table). The total physical size of the database is almost 170GB, but the actual raw size of the data was 1TB, so you can see the Infobright compression in action and that it delivers as promised.
Checking a few row counts prove the above numbers:
mysql> select count(*) from fact_sales5; +------------+ | count(*) | +------------+ | 8080000000 | +------------+ 1 row in set (0.00 sec) mysql> select count(*) from fact_sales; +------------+ | count(*) | +------------+ | 1000000000 | +------------+ 1 row in set (0.00 sec)
Notice that Infobright responds just like MyISAM in full COUNT(*) queries; the knowledge grid knows how many rows are in each table so you won’t waste time figure-tapping in waiting for a response from such queries.
Now, let’s issue a few analytic queries and see what we get. First, let’s do a simple join to find out how much the dealership made over a certain time period for one make of car:
mysql> select sum(dlr_trans_amt)
-> from fact_sales a, dim_cars b
-> where a.make_id = b.make_id and
-> b.make_name = 'ACURA' and
-> b.model_name = 'MDX' and
-> trans_date between '2007-01-01' and '2007-01-31';
+--------------------+
| sum(dlr_trans_amt) |
+--------------------+
| 11264027726 |
+--------------------+
1 row in set (24.98 sec)
Not too bad at all. But now let’s put the knowledge grid / data packs to the test and see how big a dent in our response time we get by adding eight times more data to the mix:
mysql> select sum(dlr_trans_amt)
-> from fact_sales5 a, dim_cars b
-> where a.make_id = b.make_id and
-> b.make_name = 'ACURA' and
-> b.model_name = 'MDX' and
-> trans_date between '2007-01-01' and '2007-01-31';
+--------------------+
| sum(dlr_trans_amt) |
+--------------------+
| 11264027726 |
+--------------------+
1 row in set (27.20 sec)
Nice! Infobright was able to – again – only examine the needed data packs and exclude all the other data it didn’t need to look for to satisfy our query, with no real practical impact to the overall response time (running the same query again actually came in under the first query that used the smaller fact table).
Let’s now try something that the general MySQL Server will struggle with in some cases – nested subqueries:
mysql> select avg(dlr_trans_amt)
-> from fact_sales
-> where trans_date between '2007-01-01' and '2007-12-31' and
-> dlr_trans_type = 'SALE' and make_id =
-> (select make_id
-> from dim_cars
-> where make_name = 'ASTON MARTIN' and
-> model_name = 'DB7') and
-> sales_area_id in
-> (select sales_area_id
-> from dim_sales_area
-> where sales_state =
-> (select dealer_state
-> from dim_dealers
-> where dealer_name like 'BHUTANI%'));
+--------------------+
| avg(dlr_trans_amt) |
+--------------------+
| 45531.444471505 |
+--------------------+
1 row in set (50.78 sec)
Infobright plows through the data just fine. What about UNION statements – oftentimes these can cause response issues with MySQL. Let’s try both fact tables this time:
mysql> (select avg(dlr_trans_amt), avg(sales_commission), avg(sales_discount)
-> from fact_sales
-> where trans_date between '2007-01-01' and '2007-01-31')
-> union all
-> (select avg(dlr_trans_amt), avg(sales_commission), avg(sales_discount)
-> from fact_sales
-> where trans_date between '2007-02-01' and '2007-02-28');
+--------------------+-----------------------+---------------------+
| avg(dlr_trans_amt) | avg(sales_commission) | avg(sales_discount) |
+--------------------+-----------------------+---------------------+
| 45550.1568209903 | 5.39966 | 349.50289769532 |
| 45549.5774942714 | 5.39976 | 349.498835301098 |
+--------------------+-----------------------+---------------------+
2 rows in set (0.49 sec)
mysql> (select avg(dlr_trans_amt), avg(sales_commission), avg(sales_discount)
-> from fact_sales5
-> where trans_date between '2007-01-01' and '2007-01-31')
-> union all
-> (select avg(dlr_trans_amt), avg(sales_commission), avg(sales_discount)
-> from fact_sales5
-> where trans_date between '2007-02-01' and '2007-02-28');
+--------------------+-----------------------+---------------------+
| avg(dlr_trans_amt) | avg(sales_commission) | avg(sales_discount) |
+--------------------+-----------------------+---------------------+
| 45550.1568209903 | 5.39966 | 349.50289769532 |
| 45549.5774942714 | 5.39976 | 349.498835301098 |
+--------------------+-----------------------+---------------------+
2 rows in set (0.75 sec)
It appears the UNION’s were satisfied via knowledge grid access alone. Next, let’s try a few joins coupled with a having clause and ask for the average Ashton Martin dealer transaction amounts over one year for dealers in the state of Indiana:
mysql> select fact.dealer_id,
-> avg(fact.dlr_trans_amt)
-> from fact_sales fact
-> inner join dim_cars cars on (fact.make_id = cars.make_id)
-> inner join dim_sales_area sales on
-> (fact.sales_area_id = sales.sales_area_id)
-> where fact.trans_date between '2007-01-01' and '2007-12-31' and
-> fact.dlr_trans_type = 'SALE' and
-> cars.make_name = 'ASTON MARTIN' and
-> cars.model_name = 'DB7' and
-> sales.sales_state = 'IN'
-> group by fact.dealer_id
-> having avg(fact.dlr_trans_amt) > 50000
-> order by fact.dealer_id desc;
.
.
.
| 2 | 51739.181818182 |
| 1 | 57964.8 |
+-----------+-------------------------+
317 rows in set (50.66 sec)
Of course, there are plenty of other queries that could be tested, but the above will give you a feel for how Infobright performs for some typical analytic-styled queries. And again, one of the great things is you don’t have to spend time designing indexing or partitioning schemes to get performance results like those show above because none of that is necessary in Infobright. In fact, there are only around three tuning parameters for the engine and they’re all memory related.
Infobright Limitations
There are certain limitations you need to be aware of right now with Infobright. Not all queries can be satisfied with the Infobright optimizer; those that can’t end up being sent over to the MySQL optimizer. If that happens you’ll receive a warning after your query executes that states that such a thing occurred.
- Infobright can handle up to 32 concurrent queries at this time.
- A query is currently constrained to one CPU/Core.
- Correlated subqueries are supported, but typically aren’t run that efficiently.
- DML (
insert,update,delete; only available in the Enterprise edition) only supports table-level locking, which could reduce concurrency if much DML occurs in an Infobright warehouse. - Theoretically, an Infobright table can go up to 147 trillion rows, but practically, 50 billion is the limit today – a count which greatly depends on the data row size and datatypes used (i.e. the row limit could go higher depending on the row size).
- Internationalization support is lacking right now; UTF8 support planned first half of 2009.
- Infobright supports Windows for ICE and Solaris for IEE only right now. They also have pre-built VMs available for other environments (based on VMWare.).
- No
ALTER TABLEsupport. You cannot switch from other tables to Infobright or vice versa. - The knowledge grid can’t process non-Infobright tables well so if you have a mixture of storage engines in a query that involves Infobright tables too, expect your performance to take a hit
I also hit a small bug on two of the queries above where substituting the 8 billion row table for the one billion row table caused a performance hit on the query (everything else being equal). Apparently, there is a known bug on the sorting algorithm that relates to the source data and is only experienced with large tables. Infobright is in the process of correcting it.
Right now in terms of operating system and hardware support, the Infobright storage engine runs on 32-bit (Community edition only) and 64-bit (Community and Enterprise editions) Intel and AMD Red Hat Enterprise Linux, CentOS, Fedora (Community edition only) and Debian with standard commodity hardware. And all key BI tools (Business Objects, Cognos, Pentaho, Jaspersoft, etc.) support the MySQL and Infobright combination.
Conclusions
With smart tech and business folks realizing the absolute must-have nature of data warehouses and BI support, it’s a great time to check out a MySQL-Infobright solution. You can download and try out the Community version of the Infobright storage engine at www.infobright.org. In addition, MySQL has forums for data warehousing questions at: http://forums.mysql.com/list.php?32, with more information and white papers (both tech and otherwise) being found on both the MySQL and Infobright web sites (the Infobright corporate site is www.infobright.org).
So please try out Infobright and let me know what you think. And, as always, thanks for your support of MySQL and Sun.