This section discusses how to perform a rolling restart of a MySQL Cluster installation, so called because it involves stopping and starting (or restarting) each node in turn, so that the cluster itself remains operational. This is often done as part of a rolling upgrade or rolling downgrade, where high availability of the cluster is mandatory and no downtime of the cluster as a whole is permissible. Where we refer to upgrades, the information provided here also generally applies to downgrades as well.
There are a number of reasons why a rolling restart might be desirable:
Cluster configuration change. To make a change in the cluster's configuration, such as adding an SQL node to the cluster, or setting a configuration parameter to a new value.
Cluster software upgrade/downgrade. To upgrade the cluster to a newer version of the MySQL Cluster software (or to downgrade it to an older version). This is usually referred to as a “rolling upgrade” (or “rolling downgrade”, when reverting to an older version of MySQL Cluster).
Change on node host. To make changes in the hardware or operating system on which one or more cluster nodes are running.
-
Cluster reset. To reset the cluster because it has reached an undesirable state. In such cases it is often desirable to reload the data and metadata of one or more data nodes. This can be done 1 of 3 ways:
Start each data node process (ndbd, or possibly ndbmtd in MySQL Cluster NDB 7.0 and later) with the
--initialoption, which forces the data node to clear its filesystem and reload data and metadata from the other data nodes.-
Create a backup using the ndb_mgm client
BACKUPcommand prior to performing the restart. Following the upgrade, restore the node or nodes using ndb_restore.See Section 17.5.3, “Online Backup of MySQL Cluster”, and Section 17.4.17, “ndb_restore — Restore a MySQL Cluster Backup”, for more information.
Use mysqldump (see Section 4.5.4, “mysqldump — A Database Backup Program”) to create a backup prior to the upgrade; afterwards, restore the dump using
LOAD DATA INFILE.
Freeing of resources. To allow memory allocated to a table by successive
INSERTandDELETEoperations to be freed for re-use by other MySQL Cluster tables.
The process for performing a rolling restart may be generalized as follows:
Stop all cluster management nodes (ndb_mgmd processes), reconfigure them, then restart them.
Stop, reconfigure, then restart each cluster data node (ndbd process) in turn.
Stop, reconfigure, then restart each cluster SQL node (mysqld process) in turn.
The specifics for implementing a particular rolling upgrade depend upon the actual changes being made. A more detailed view of the process is presented here:
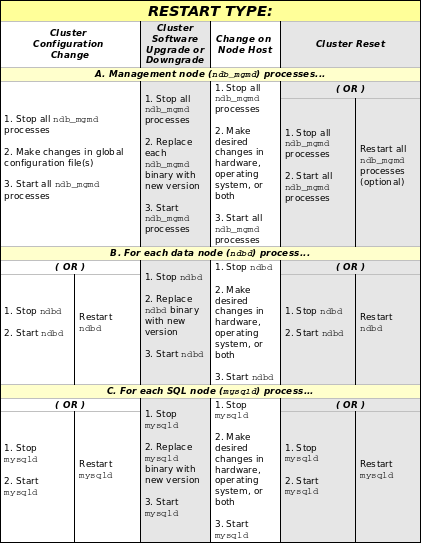
In the previous diagram, the
Stop and
Start steps indicate that the
process must be stopped completely using a shell command (such
as kill on most Unix systems) or the
management client STOP command, then started
again from a system shell by invoking the
ndbd or ndb_mgmd
executable as appropriate.
Restart indicates the process
may be restarted using the ndb_mgm management
client RESTART command.
Prior to MySQL Cluster NDB 6.3.29 and MySQL Cluster NDB 7.0.10. When performing an upgrade or downgrade of the cluster software, you must upgrade or downgrade the management nodes first, then the data nodes, and finally the SQL nodes. Doing so in any other order may leave the cluster in an unusable state.
MySQL Cluster NDB 6.3.29 and later; MySQL Cluster NDB 7.0.10 and later. MySQL Cluster supports a more flexible order for upgrading the cluster nodes. When upgrading a cluster running MySQL Cluster NDB 6.3.29 or later, or a cluster that is running MySQL Cluster NDB 7.0.10 or later, you may upgrade API nodes (including SQL nodes) before upgrading the management nodes, data nodes, or both. In other words, you are permitted to upgrade the API and SQL nodes in any order. This is subject to the following provisions:
This functionality is intended for use as part of an online upgrade only. A mix of node binaries from different MySQL Cluster releases is neither intended nor supported for constant, long-term use in a production setting.
All management nodes must be upgraded before any data nodes are upgraded. This remains true regardless of the order in which you upgrade the cluster's API and SQL nodes.
For MySQL Cluster NDB 6.3, the ability to upgrade API nodes in any order relative to upgading management nodes and data nodes is supported only for MySQL Cluster NDB 6.3.29 and later; for MySQL Cluster NDB 7.0, it supported only for MySQL Cluster NDB 7.0.10 and later. This means that, if you are upgrading from a MySQL Cluster NDB 6.3 release to a MySQL Cluster NDB 7.0 release, the “old”
NDBengine version must be 6.3.29 or later, and the “new”NDBengine version must be 7.0.10 or later.-
When upgrading the cluster from a MySQL Cluster NDB 6.3 release to a MySQL Cluster NDB 7.0 release: Once you have started upgraded the API nodes, you should not perform DDL operations until all management nodes and data nodes have been upgraded. DML operations should be unaffected, and can continue while the upgrade is in progress.
However, it is possible to perform DDL from an “old” (NDB 6.3 version) API node as long as the master data node is also running the “old” version of MySQL Cluster. You should keep in mind that a data node restart could result in the master node running a “new” (NDB 7.0 version) binary while one or more data nodes are still using the “old” (NDB 6.3) version; in this situation, no DDL can be performed from any API node, because the master data node is no longer using an NDB 6.3 binary, but the cluster still contains nodes which are not yet using NDB 7.0. For this reason, we recommend that you avoid performing DDL at any time while the upgrade is in progress.
-
Features specific to the “new” version must not be used until all management nodes and data nodes have been upgraded.
This also applies to any MySQL Server version change that may apply, in addition to the NDB engine version change, so do not forget to take this into account when planning the upgrade. (This is true for online upgrades of MySQL Cluster in general.)
User Comments
I am not sure if the following is documented, so I am putting in here. We used Server version: 5.0.45 MySQL Community Server (GPL)
It appears that ndbd rolling restarts wait for transactions to commit, but eventually time out and close the uncommited connection.
I think this is good behavior, it cleans up stalled transactions that would probably fail anyway, and then starts the node.
This came out of a lot of interesting scenarios spanning rolling restarts. We only start and stop ndbd. We have 2 ndb notes containing all the data, node 6 and 7.
I used two terminals, indicated below by prompts ndb_mgm> and mysql>. Read above how "restart -n" is like stop, but it can be started later from the ndb_mgm. Here is how I did the experiment:
ndb_mgm> 7 start
ndb_mgm> 6 restart -n
### This effectively stops node 6
ndb_mgm> show
### Observe node 6 is down, 7 is up
mysql> start transaction;
mysql> insert ...;
ndb_mgm> 6 start
ndb_mgm> show
### Node 6 six will stay in a "Starting" state for several minutes.
### if you commit the transaction, 6 will immediately start.
### if you wait until node 6 starts, 5 or 10 minutes, the following happens in the mysql client terminal:
mysql> select * from ...;
ERROR 2006 (HY000): MySQL server has gone away
No connection. Trying to reconnect...
Connection id: 165066
Current database: *** NONE ***
### Observe that the insert transaction was rolled back.
### That's it.
Speculative conclusion: rolling restarts wait for commits, but eventually time out and close the uncommitted connection.
Add your own comment.