
![]()
Version
0.1.14
License
MIT + file LICENSE
Peter Meissner retep.meissner@gmail.com [aut, cre]
Description
Base R already ships with string handling capabilities ‘out- of-the-box’ but lacks streamlined function names and workflow. The ‘stringi’ (‘stringr’) package on the other hand has well named functions, extensive Unicode support and allows for a streamlined workflow. On the other hand it adds dependencies and regular expression interpretation between base R functions and ‘stringi’ functions might differ. This packages aims at providing a solution to the use case of unwanted dependencies on the one hand but the need for streamlined text processing on the other. The packages’ functions are solely based on wrapping base R functions into ‘stringr’/‘stringi’ like function names. Along the way it adds one or two extra functions and last but not least provides all functions as generics, therefore allowing for adding methods for other text structures besides plain character vectors.
This packages aims at:
This package does not aim at:
Note, that this package uses a Contributor Code of Conduct. By participating in this project you agree to abide by its terms: http://contributor-covenant.org/version/1/0/0/ (basically this should be a place were people get along with each other respectful and nice because it’s simply more fun that way for everybody)
Contributions are very much welcome, e.g. in the form of:
dev version
stable version
library(stringb)
objects("package:stringb")
## [1] "%.%" "%..%" "text_c"
## [4] "text_collapse" "text_count" "text_delete"
## [7] "text_detect" "text_dup" "text_eval"
## [10] "text_extract" "text_extract_all" "text_extract_group"
## [13] "text_extract_group_all" "text_filter" "text_grep"
## [16] "text_grepl" "text_grepv" "text_length"
## [19] "text_locate" "text_locate_all" "text_locate_group"
## [22] "text_nchar" "text_pad" "text_read"
## [25] "text_rep" "text_replace" "text_replace_all"
## [28] "text_replace_group" "text_replace_locates" "text_show"
## [31] "text_snippet" "text_split" "text_split_n"
## [34] "text_sub" "text_subset" "text_to_lower"
## [37] "text_to_title_case" "text_to_upper" "text_tokenize"
## [40] "text_tokenize_lines" "text_tokenize_sentences" "text_tokenize_words"
## [43] "text_trim" "text_which" "text_which_value"
## [46] "text_wrap" "text_write"library(stringb)
(test_file <- stringb:::test_file("rc_1_ch1.txt")) # just a file accompanying the package to test things
## [1] "C:/home/documents/R/win-library/3.6/stringb/testfiles/rc_1_ch1.txt"
text_read( test_file, tokenize = "\\W", n=20)[67:79]
## [1] "Project" "Gutenberg" "License" "included" "with" "this" "eBook" "or"
## [9] "online" "at" "www" "gutenberg" "org"Although, text_read() is just a wrapper around readLines() it has become more powerful, consistent and streamlined by (1) always producing UTF-8 encoded character vectors, (2) allowing the usage of all readLines() options - e.g. n, (3) and adding further useful functionality like on-the-fly-tokenization.
library(stringb)
(test_file <- stringb:::test_file("rc_3.txt")) # just a file accompanying the package to test things
## [1] "C:/home/documents/R/win-library/3.6/stringb/testfiles/rc_3.txt"
text <- text_read(test_file, tokenize = "\\W+")
friday_occurs <- text_detect(text, "FRIDAY", ignore.case=TRUE)
plot(friday_occurs, type = "n")
abline(v=which(friday_occurs))
title("Friday Appearing in Robinson Crusoe")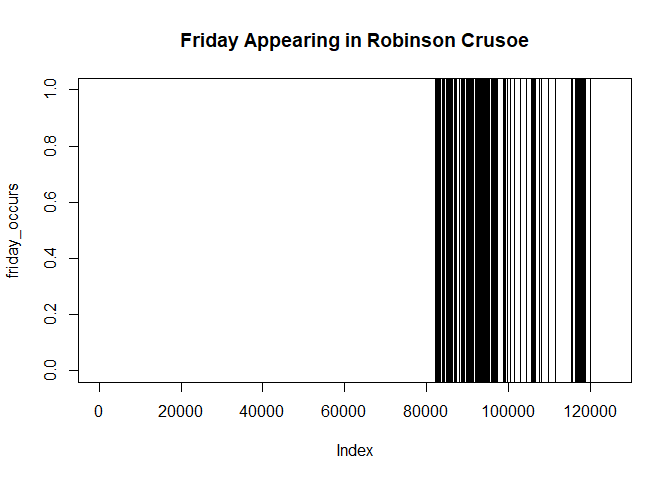
Text_detect() is another example for a streamlined interface (easier to remember than grepl) with all base-R whistles and bells still being there - almost all base-R pattern matching functions have the ignore.case options to make pattern matching case insensitive.
library(stringb)
(test_file <- stringb:::test_file("rc_3.txt")) # just a file accompanying the package to test things
## [1] "C:/home/documents/R/win-library/3.6/stringb/testfiles/rc_3.txt"
text <- text_read(test_file)
plot(text, pattern="Friday", ignore.case=TRUE)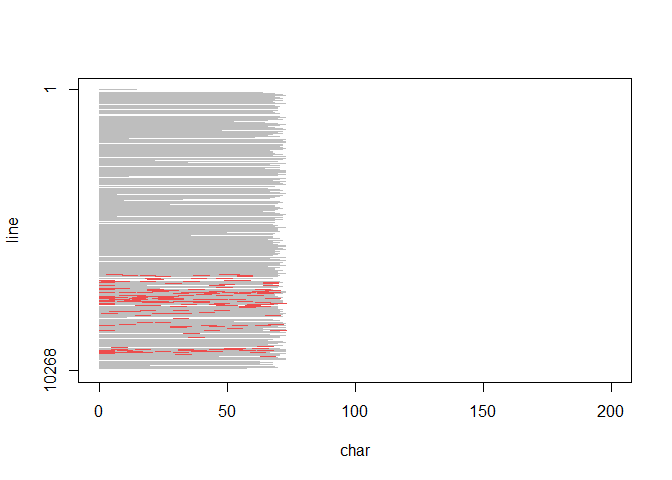
A simple method to plot character vectors with pattern markup was added as well.