![]()
![]()

You can install the sparklyr package from CRAN as follows:
You should also install a local version of Spark for development purposes:
To upgrade to the latest version of sparklyr, run the following command and restart your r session:
You can connect to both local instances of Spark as well as remote Spark clusters. Here we’ll connect to a local instance of Spark via the spark_connect function:
The returned Spark connection (sc) provides a remote dplyr data source to the Spark cluster.
For more information on connecting to remote Spark clusters see the Deployment section of the sparklyr website.
We can now use all of the available dplyr verbs against the tables within the cluster.
We’ll start by copying some datasets from R into the Spark cluster (note that you may need to install the nycflights13 and Lahman packages in order to execute this code):
library(dplyr)
iris_tbl <- copy_to(sc, iris, overwrite = TRUE)
flights_tbl <- copy_to(sc, nycflights13::flights, "flights", overwrite = TRUE)
batting_tbl <- copy_to(sc, Lahman::Batting, "batting", overwrite = TRUE)
src_tbls(sc)## [1] "batting" "flights" "iris"To start with here’s a simple filtering example:
## # Source: spark<?> [?? x 19]
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 1 1 517 515 2 830 819
## 2 2013 1 1 542 540 2 923 850
## 3 2013 1 1 702 700 2 1058 1014
## 4 2013 1 1 715 713 2 911 850
## 5 2013 1 1 752 750 2 1025 1029
## 6 2013 1 1 917 915 2 1206 1211
## 7 2013 1 1 932 930 2 1219 1225
## 8 2013 1 1 1028 1026 2 1350 1339
## 9 2013 1 1 1042 1040 2 1325 1326
## 10 2013 1 1 1231 1229 2 1523 1529
## # … with more rows, and 11 more variables: arr_delay <dbl>, carrier <chr>,
## # flight <int>, tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>,
## # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>Introduction to dplyr provides additional dplyr examples you can try. For example, consider the last example from the tutorial which plots data on flight delays:
delay <- flights_tbl %>%
group_by(tailnum) %>%
summarise(count = n(), dist = mean(distance), delay = mean(arr_delay)) %>%
filter(count > 20, dist < 2000, !is.na(delay)) %>%
collect
# plot delays
library(ggplot2)
ggplot(delay, aes(dist, delay)) +
geom_point(aes(size = count), alpha = 1/2) +
geom_smooth() +
scale_size_area(max_size = 2)## `geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'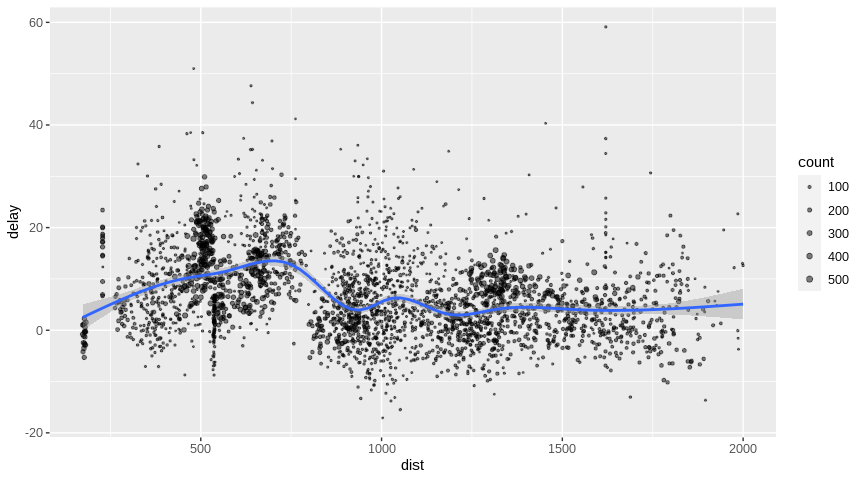
dplyr window functions are also supported, for example:
batting_tbl %>%
select(playerID, yearID, teamID, G, AB:H) %>%
arrange(playerID, yearID, teamID) %>%
group_by(playerID) %>%
filter(min_rank(desc(H)) <= 2 & H > 0)## # Source: spark<?> [?? x 7]
## # Groups: playerID
## # Ordered by: playerID, yearID, teamID
## playerID yearID teamID G AB R H
## <chr> <int> <chr> <int> <int> <int> <int>
## 1 aaronha01 1959 ML1 154 629 116 223
## 2 aaronha01 1963 ML1 161 631 121 201
## 3 aaronto01 1962 ML1 141 334 54 77
## 4 aaronto01 1968 ATL 98 283 21 69
## 5 abadfe01 2012 HOU 37 7 0 1
## 6 abbated01 1905 BSN 153 610 70 170
## 7 abbated01 1904 BSN 154 579 76 148
## 8 abbeych01 1894 WAS 129 523 95 164
## 9 abbeych01 1895 WAS 133 516 102 142
## 10 abbotda01 1890 TL2 3 7 0 1
## # … with more rowsFor additional documentation on using dplyr with Spark see the dplyr section of the sparklyr website.
It’s also possible to execute SQL queries directly against tables within a Spark cluster. The spark_connection object implements a DBI interface for Spark, so you can use dbGetQuery to execute SQL and return the result as an R data frame:
## Sepal_Length Sepal_Width Petal_Length Petal_Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5.0 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosaYou can orchestrate machine learning algorithms in a Spark cluster via the machine learning functions within sparklyr. These functions connect to a set of high-level APIs built on top of DataFrames that help you create and tune machine learning workflows.
Here’s an example where we use ml_linear_regression to fit a linear regression model. We’ll use the built-in mtcars dataset, and see if we can predict a car’s fuel consumption (mpg) based on its weight (wt), and the number of cylinders the engine contains (cyl). We’ll assume in each case that the relationship between mpg and each of our features is linear.
# copy mtcars into spark
mtcars_tbl <- copy_to(sc, mtcars, overwrite = TRUE)
# transform our data set, and then partition into 'training', 'test'
partitions <- mtcars_tbl %>%
filter(hp >= 100) %>%
mutate(cyl8 = cyl == 8) %>%
sdf_partition(training = 0.5, test = 0.5, seed = 1099)
# fit a linear model to the training dataset
fit <- partitions$training %>%
ml_linear_regression(response = "mpg", features = c("wt", "cyl"))
fit## Formula: mpg ~ wt + cyl
##
## Coefficients:
## (Intercept) wt cyl
## 33.499452 -2.818463 -0.923187For linear regression models produced by Spark, we can use summary() to learn a bit more about the quality of our fit, and the statistical significance of each of our predictors.
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.752 -1.134 -0.499 1.296 2.282
##
## Coefficients:
## (Intercept) wt cyl
## 33.499452 -2.818463 -0.923187
##
## R-Squared: 0.8274
## Root Mean Squared Error: 1.422Spark machine learning supports a wide array of algorithms and feature transformations and as illustrated above it’s easy to chain these functions together with dplyr pipelines. To learn more see the machine learning section.
You can read and write data in CSV, JSON, and Parquet formats. Data can be stored in HDFS, S3, or on the local filesystem of cluster nodes.
temp_csv <- tempfile(fileext = ".csv")
temp_parquet <- tempfile(fileext = ".parquet")
temp_json <- tempfile(fileext = ".json")
spark_write_csv(iris_tbl, temp_csv)
iris_csv_tbl <- spark_read_csv(sc, "iris_csv", temp_csv)
spark_write_parquet(iris_tbl, temp_parquet)
iris_parquet_tbl <- spark_read_parquet(sc, "iris_parquet", temp_parquet)
spark_write_json(iris_tbl, temp_json)
iris_json_tbl <- spark_read_json(sc, "iris_json", temp_json)
src_tbls(sc)## [1] "batting" "flights" "iris" "iris_csv" "iris_json"
## [6] "iris_parquet" "mtcars"You can execute arbitrary r code across your cluster using spark_apply. For example, we can apply rgamma over iris as follows:
## # Source: spark<?> [?? x 4]
## Sepal_Length Sepal_Width Petal_Length Petal_Width
## <dbl> <dbl> <dbl> <dbl>
## 1 8.80 7.20 5.10 3.90
## 2 8.60 6.70 5.10 3.90
## 3 8.40 6.90 5.00 3.90
## 4 8.30 6.80 5.20 3.90
## 5 8.70 7.30 5.10 3.90
## 6 9.10 7.60 5.40 4.10
## 7 8.30 7.10 5.10 4.00
## 8 8.70 7.10 5.20 3.90
## 9 8.10 6.60 5.10 3.90
## 10 8.60 6.80 5.20 3.80
## # … with more rowsYou can also group by columns to perform an operation over each group of rows and make use of any package within the closure:
spark_apply(
iris_tbl,
function(e) broom::tidy(lm(Petal_Width ~ Petal_Length, e)),
columns = c("term", "estimate", "std.error", "statistic", "p.value"),
group_by = "Species"
)## # Source: spark<?> [?? x 6]
## Species term estimate std.error statistic p.value
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 setosa (Intercept) -0.0482 0.122 -0.396 6.94e- 1
## 2 setosa Petal_Length 0.201 0.0826 2.44 1.86e- 2
## 3 versicolor (Intercept) -0.0843 0.161 -0.525 6.02e- 1
## 4 versicolor Petal_Length 0.331 0.0375 8.83 1.27e-11
## 5 virginica (Intercept) 1.14 0.379 2.99 4.34e- 3
## 6 virginica Petal_Length 0.160 0.0680 2.36 2.25e- 2The facilities used internally by sparklyr for its dplyr and machine learning interfaces are available to extension packages. Since Spark is a general purpose cluster computing system there are many potential applications for extensions (e.g. interfaces to custom machine learning pipelines, interfaces to 3rd party Spark packages, etc.).
Here’s a simple example that wraps a Spark text file line counting function with an R function:
# write a CSV
tempfile <- tempfile(fileext = ".csv")
write.csv(nycflights13::flights, tempfile, row.names = FALSE, na = "")
# define an R interface to Spark line counting
count_lines <- function(sc, path) {
spark_context(sc) %>%
invoke("textFile", path, 1L) %>%
invoke("count")
}
# call spark to count the lines of the CSV
count_lines(sc, tempfile)## [1] 336777To learn more about creating extensions see the Extensions section of the sparklyr website.
You can cache a table into memory with:
and unload from memory using:
You can view the Spark web console using the spark_web function:
You can show the log using the spark_log function:
## 20/04/15 11:49:57 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 70 (/tmp/Rtmp3NF2Jb/filece955cc88fe.csv MapPartitionsRDD[336] at textFile at NativeMethodAccessorImpl.java:0) (first 15 tasks are for partitions Vector(0))
## 20/04/15 11:49:57 INFO TaskSchedulerImpl: Adding task set 70.0 with 1 tasks
## 20/04/15 11:49:57 INFO TaskSetManager: Starting task 0.0 in stage 70.0 (TID 78, localhost, executor driver, partition 0, PROCESS_LOCAL, 7900 bytes)
## 20/04/15 11:49:57 INFO Executor: Running task 0.0 in stage 70.0 (TID 78)
## 20/04/15 11:49:57 INFO HadoopRDD: Input split: file:/tmp/Rtmp3NF2Jb/filece955cc88fe.csv:0+33313106
## 20/04/15 11:49:57 INFO Executor: Finished task 0.0 in stage 70.0 (TID 78). 832 bytes result sent to driver
## 20/04/15 11:49:57 INFO TaskSetManager: Finished task 0.0 in stage 70.0 (TID 78) in 196 ms on localhost (executor driver) (1/1)
## 20/04/15 11:49:57 INFO TaskSchedulerImpl: Removed TaskSet 70.0, whose tasks have all completed, from pool
## 20/04/15 11:49:57 INFO DAGScheduler: ResultStage 70 (count at NativeMethodAccessorImpl.java:0) finished in 0.200 s
## 20/04/15 11:49:57 INFO DAGScheduler: Job 47 finished: count at NativeMethodAccessorImpl.java:0, took 0.204883 sFinally, we disconnect from Spark:
The latest RStudio Preview Release of the RStudio IDE includes integrated support for Spark and the sparklyr package, including tools for:
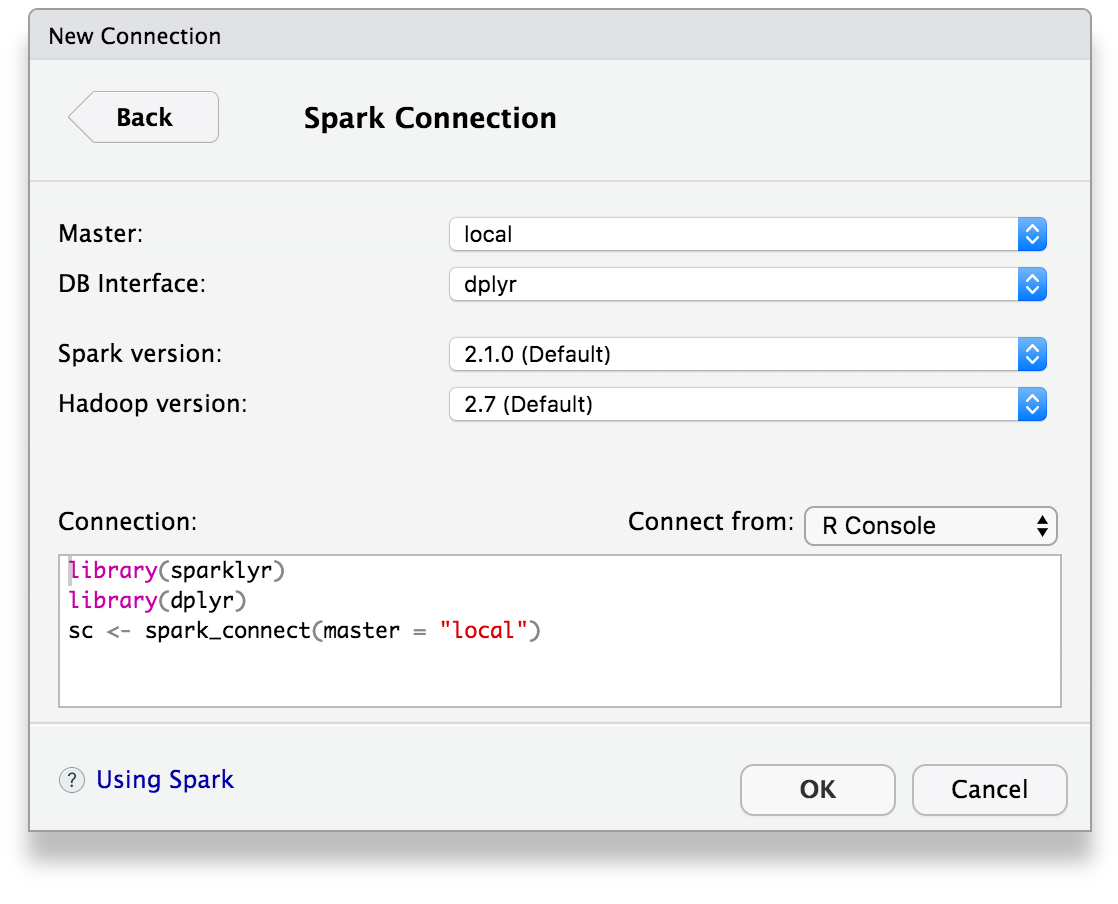
Once you’ve installed the sparklyr package, you should find a new Spark pane within the IDE. This pane includes a New Connection dialog which can be used to make connections to local or remote Spark instances:
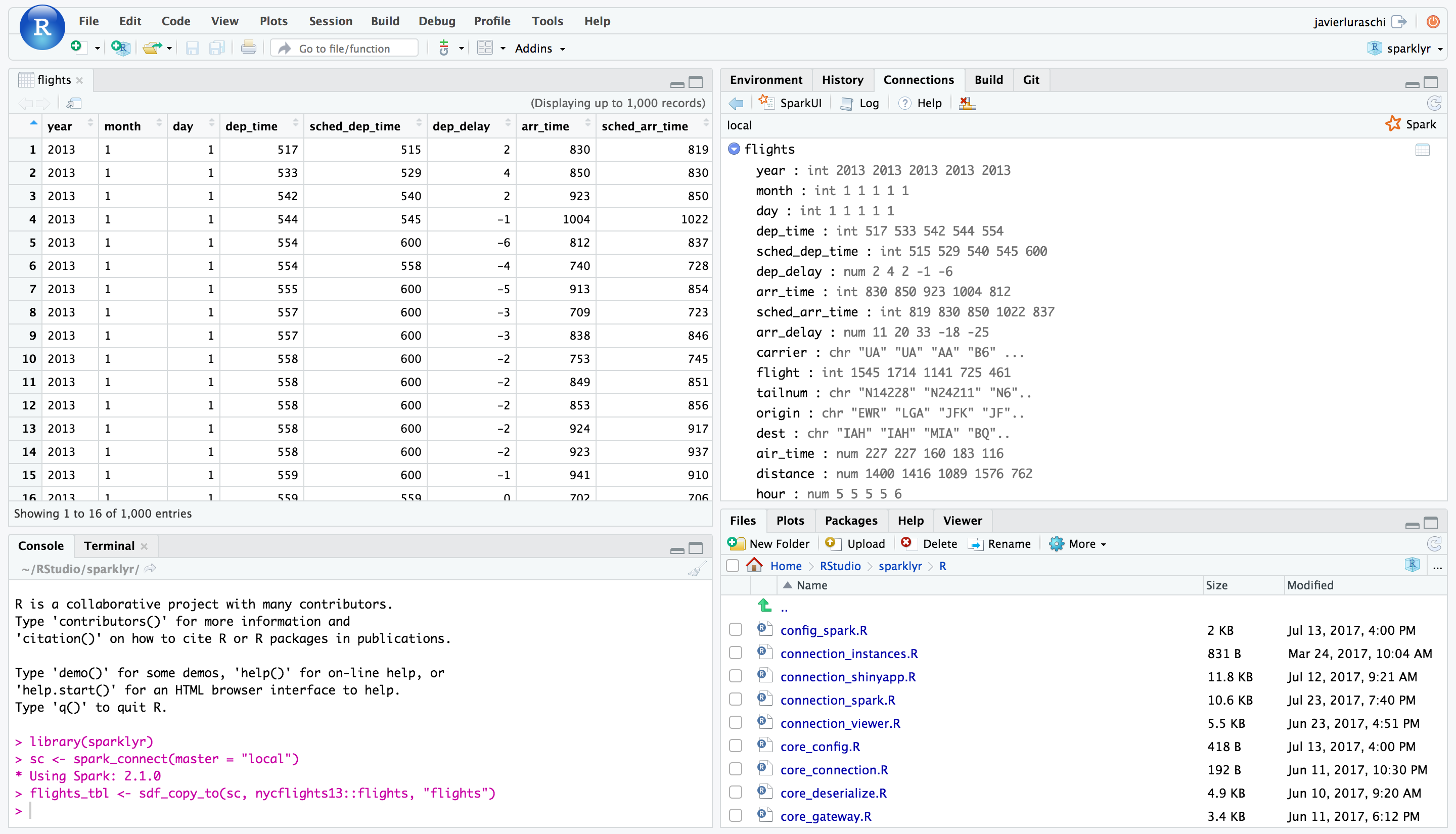
Once you’ve connected to Spark you’ll be able to browse the tables contained within the Spark cluster and preview Spark DataFrames using the standard RStudio data viewer:
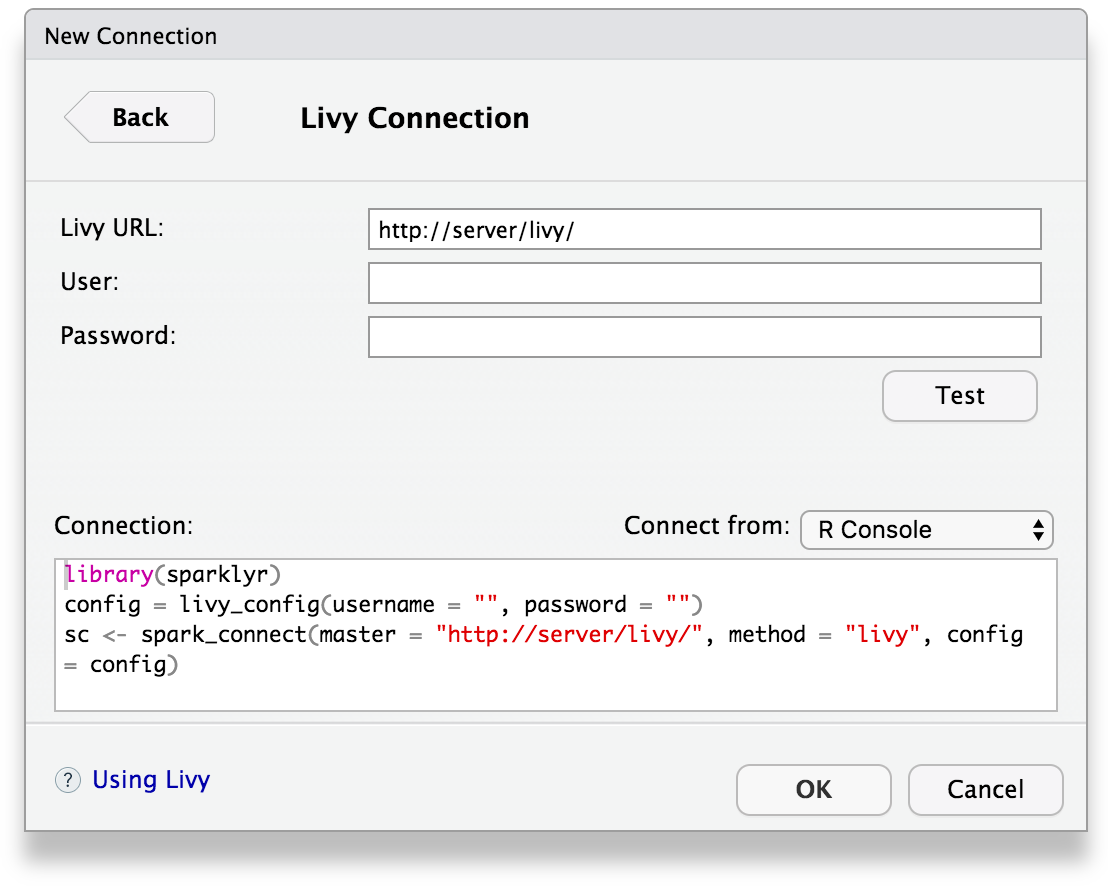
You can also connect to Spark through Livy through a new connection dialog:
The RStudio IDE features for sparklyr are available now as part of the RStudio Preview Release.
rsparkling is a CRAN package from H2O that extends sparklyr to provide an interface into Sparkling Water. For instance, the following example installs, configures and runs h2o.glm:
library(rsparkling)
library(sparklyr)
library(dplyr)
library(h2o)
sc <- spark_connect(master = "local", version = "2.3.2")
mtcars_tbl <- copy_to(sc, mtcars, "mtcars", overwrite = TRUE)
mtcars_h2o <- as_h2o_frame(sc, mtcars_tbl, strict_version_check = FALSE)
mtcars_glm <- h2o.glm(x = c("wt", "cyl"),
y = "mpg",
training_frame = mtcars_h2o,
lambda_search = TRUE)## Model Details:
## ==============
##
## H2ORegressionModel: glm
## Model ID: GLM_model_R_1527265202599_1
## GLM Model: summary
## family link regularization
## 1 gaussian identity Elastic Net (alpha = 0.5, lambda = 0.1013 )
## lambda_search
## 1 nlambda = 100, lambda.max = 10.132, lambda.min = 0.1013, lambda.1se = -1.0
## number_of_predictors_total number_of_active_predictors
## 1 2 2
## number_of_iterations training_frame
## 1 100 frame_rdd_31_ad5c4e88ec97eb8ccedae9475ad34e02
##
## Coefficients: glm coefficients
## names coefficients standardized_coefficients
## 1 Intercept 38.941654 20.090625
## 2 cyl -1.468783 -2.623132
## 3 wt -3.034558 -2.969186
##
## H2ORegressionMetrics: glm
## ** Reported on training data. **
##
## MSE: 6.017684
## RMSE: 2.453097
## MAE: 1.940985
## RMSLE: 0.1114801
## Mean Residual Deviance : 6.017684
## R^2 : 0.8289895
## Null Deviance :1126.047
## Null D.o.F. :31
## Residual Deviance :192.5659
## Residual D.o.F. :29
## AIC :156.2425Livy enables remote connections to Apache Spark clusters. However, please notice that connecting to Spark clusters through Livy is much slower than any other connection method.
Before connecting to Livy, you will need the connection information to an existing service running Livy. Otherwise, to test livy in your local environment, you can install it and run it locally as follows:
To connect, use the Livy service address as master and method = "livy" in spark_connect. Once connection completes, use sparklyr as usual, for instance:
sc <- spark_connect(master = "http://localhost:8998", method = "livy", version = "2.4.0")
copy_to(sc, iris, overwrite = TRUE)## # Source: spark<iris> [?? x 5]
## Sepal_Length Sepal_Width Petal_Length Petal_Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## # … with more rowsOnce you are done using livy locally, you should stop this service with:
To connect to remote livy clusters that support basic authentication connect as:
config <- livy_config(username="<username>", password="<password>")
sc <- spark_connect(master = "<address>", method = "livy", config = config)
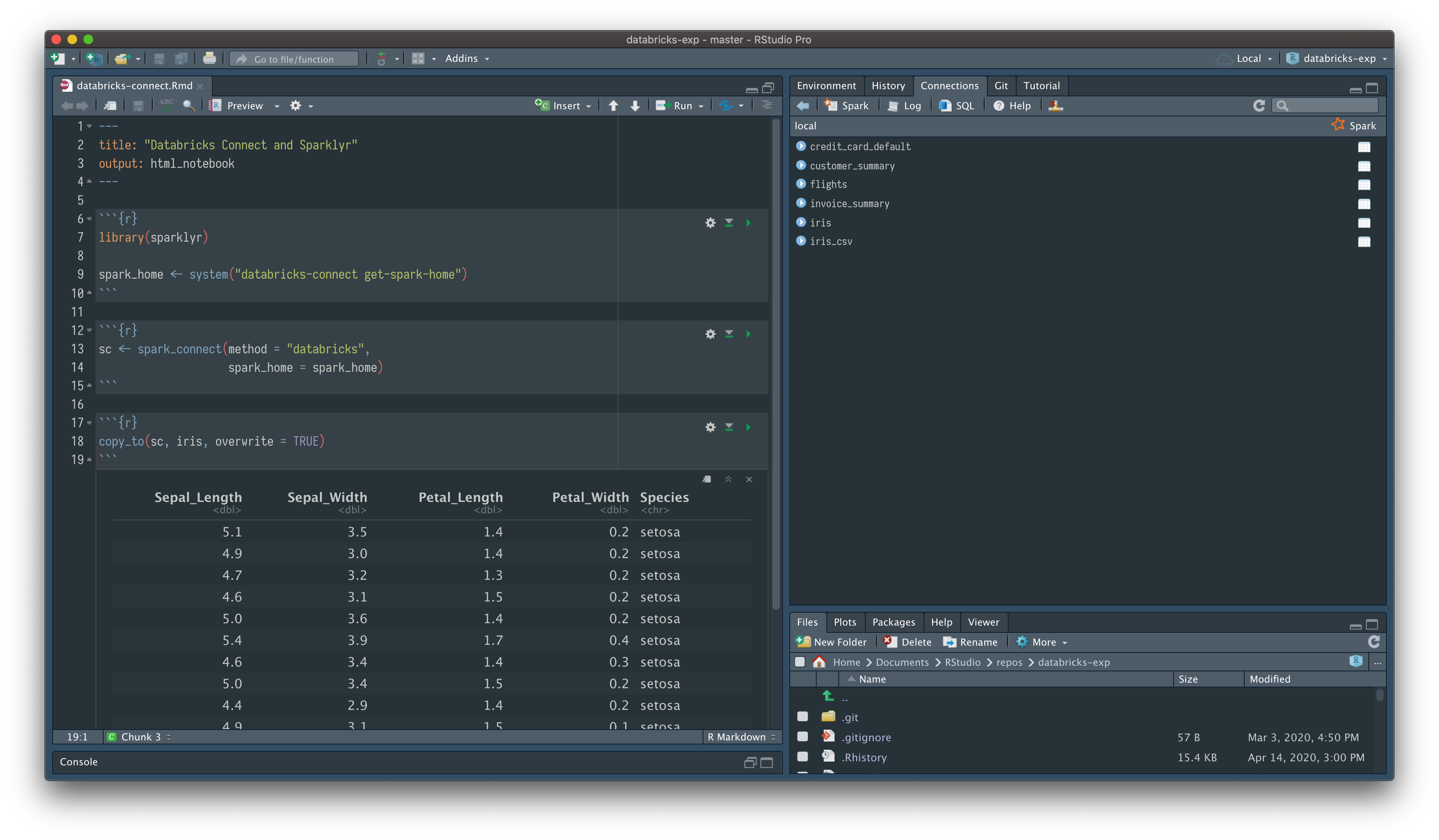
spark_disconnect(sc)Databricks Connect allows you to connect sparklyr to a remote Databricks Cluster. You can install Databricks Connect Python pakcage and use it to submit Spark jobs written in sparklyr APIs and have them execute remotely on a Databricks cluster instead of in the local Spark session.
To use sparklyr with Databricks Connect first launch a Cluster on Databricks. Then follow these instructions to setup the client:
databricks-connect configure and provide the configuration information
ttps://<account>.cloud.databricks.com.15001)Now simply create a spark connection as follows
spark_home <- system("databricks-connect get-spark-home")
sc <- spark_connect(method = "databricks",
spark_home = spark_home)
copy_to(sc, iris, overwrite = TRUE)