
![]()
Implement in one line of code a shareable web app to compare supervised machine learning regression models!
With shinyML, you can compare your favorite regression models issued from H2O or Spark frameworks without any effort.
The package can be installed from CRAN:
You can also install the latest development version from github:
This is a basic example which shows you how to run the app:
library(shinyML)
longley2 <- longley %>% mutate(Year = as.Date(as.character(Year),format = "%Y"))
shiny_h2o(data =longley2,y = "GNP",date_column = "Year",share_app = FALSE)Before running machine learning models, it can be useful to inspect the distribution of each variable and to have an insight of dependencies between explicative variables. Bothshiny_h2o and shiny_spark functions allows to check classes of explicative variables, plot histograms of each distribution and show correlation matrix between all variables. This tabs can be used to determine if some variable are strongly correlated to another and eventually removed from the training phase.You can also plot variation of every variable as a function of another using the “Explore dataset” tab.
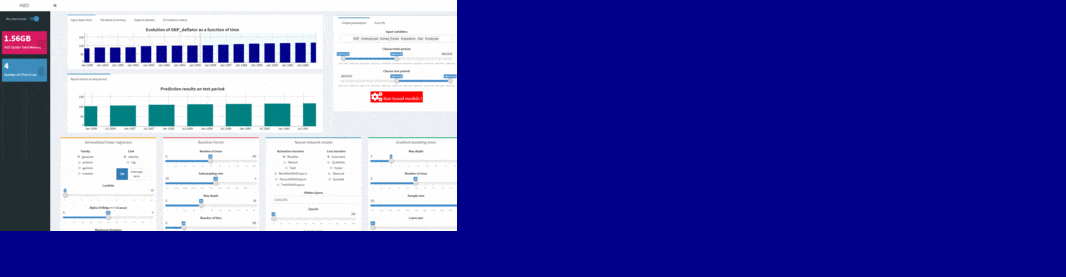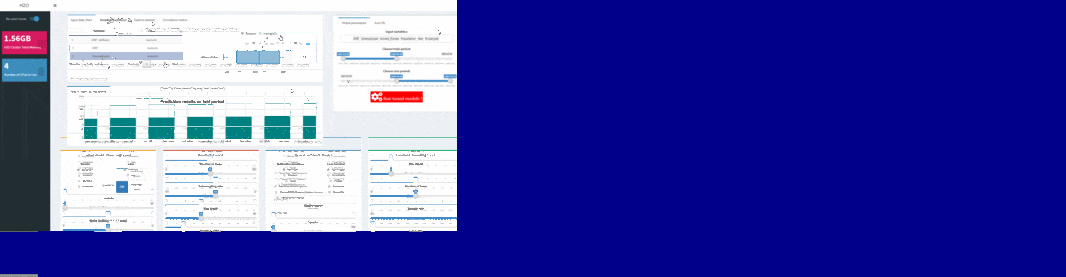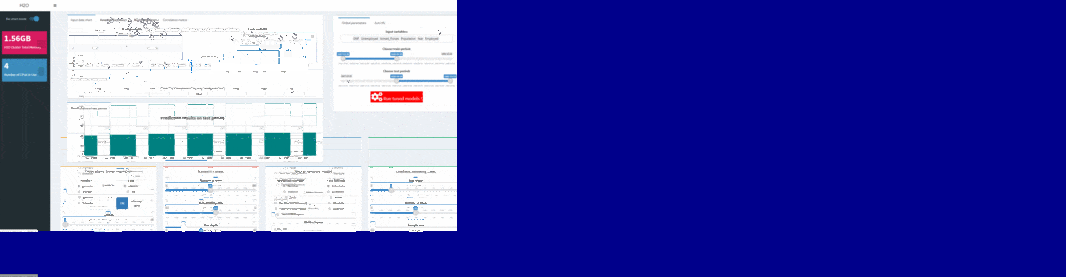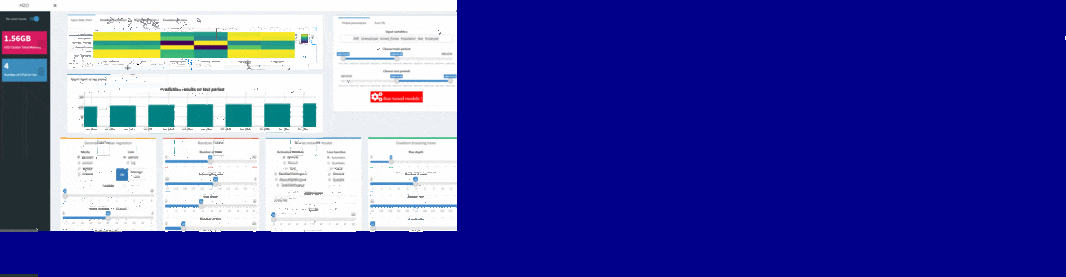
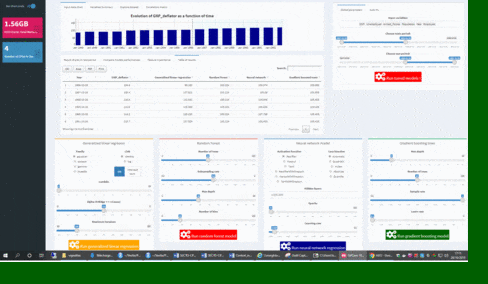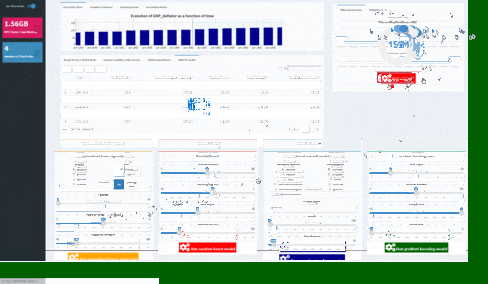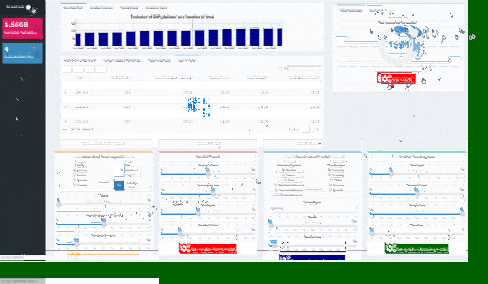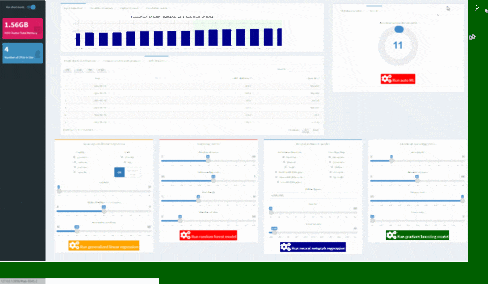
To test machine learning models on shinyML package, the first step consist in choosing separating train and test period from your dataset: this can be done in one second using slider button on the right of your shinyML app. You can also remove variables from your initial selection directly from app just simply using “Input variable” textbox. You are then free to select hyper-parameters configuration for your favorite machine learning model.
Note that hidden layers of deep learning technique can be set inside the corresponding text box: the default c(200,200) configuration corresponds to a two hiden-layers neural network, with neurons for each layers.

You can easily use shinyML package to compare the four machine learning techniques with your own hyper-parameters configuration. For that, you will just need to use shiny app buttons corresponding to your parameters and click then to “Run tuned models !”
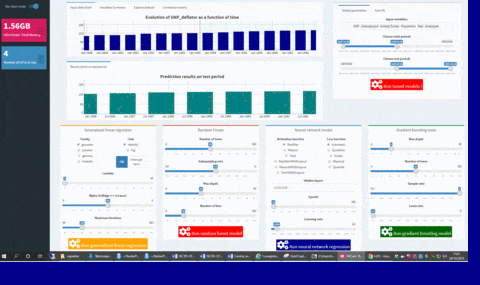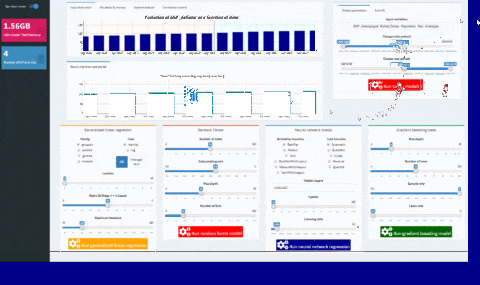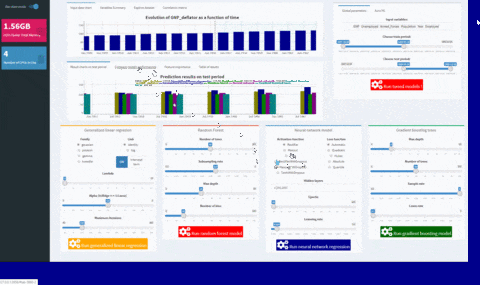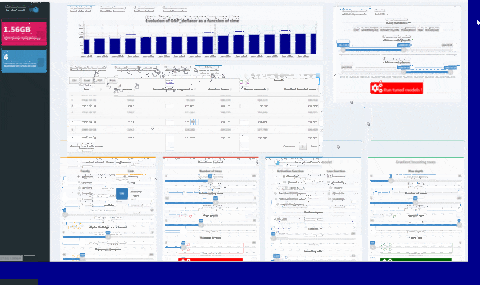
You will see a validation message box once all models have been trained: at that point, you can have an overview of your results comparing variables importances and error metrics like MAPE or RMSE.
AutoML algorithm will automatically find the best algorithm to suit your regression task: the user will be informed of the machine learning technique used and know which hyper-parameters should be configured.
The only setting that must be adjusted by the user is the maximum time authorized for searching.
For more information take a look at the package vignette.