Status
![]()
Version
0.1.21
2019-01-20 (last change to R folder)
Description
For natural language processing and analysis of qualitative text coding structures which provide a way to bind together text and text data are fundamental. The package provides such a structure and accompanying methods in form of R6 objects. The ‘rtext’ class allows for text handling and text coding (character or regex based) including data updates on text transformations as well as aggregation on various levels. Furthermore, the usage of R6 enables inheritance and passing by reference which should enable ‘rtext’ instances to be used as back-end for R based graphical text editors or text coding GUIs.
Funding
This software was created as part of the “Institutional Design in Western European Democracies” research project, funded by DFG (Deutsche Forschungsgemeinschaft), lead by Ulrich Sieberer and based at University Konstanz.
License
MIT + file LICENSE
Peter Meissner [aut, cre], Ulrich Sieberer [cph], University of Konstanz [cph]
Citation
Meißner P (2019). rtext. R package version 0.1.21, <URL: https://github.com/petermeissner/rtext>.
Sieberer U, Meißner P, Keh J, Müller W (2016). “Mapping and Explaining Parliamentary Rule Changes in Europe: A Research Program.” Legislative Studies Quarterly, 41(1), 61-88. ISSN 1939-9162, doi: 10.1111/lsq.12106 (URL: http://doi.org/10.1111/lsq.12106), <URL: http://dx.doi.org/10.1111/lsq.12106>.
To see these entries in BibTeX format, use ‘print(
BibTex for citing
@Manual{Meissner2019, title = {rtext}, author = {Peter Meißner}, year = {2019}, note = {R package version 0.1.21}, url = {https://github.com/petermeissner/rtext}, }
@Article{Sieberer2016, title = {Mapping and Explaining Parliamentary Rule Changes in Europe: A Research Program}, author = {Ulrich Sieberer and Peter Meißner and Julia F. Keh and Wolfgang C. Müller}, journal = {Legislative Studies Quarterly}, volume = {41}, number = {1}, issn = {1939-9162}, url = {http://dx.doi.org/10.1111/lsq.12106}, doi = {10.1111/lsq.12106}, pages = {61–88}, year = {2016}, }
Installation
stable CRAN version
(stable) development version
standard_repos <- options("repos")$repos
install.packages( "rtext", repos = c(standard_repos, "https://petermeissner.github.io/drat/"))
library(rtext)
Package Contents
## Loading required package: stringb## [1] "%>%" "modus" "prometheus_early" "prometheus_late" "R6_rtext_extended"
## [6] "rtext" "rtext_base" "rtext_export" "rtext_loadsave" "rtext_tokenize"
Contribution
Note, that this package uses a Contributor Code of Conduct. By participating in this project you agree to abide by its terms: http://contributor-covenant.org/version/1/0/0/ (basically this should be a place were people get along with each other respectful and nice because it’s simply more fun that way for everybody)
Contributions are very much welcome, e.g. in the form of:
Example Usage
… starting up …
… creating a text object …
# initialize (with text or file)
quote_text <- "Outside of a dog, a book is man's best friend. Inside of a dog it's too dark to read."
quote <- rtext$new(text = quote_text)## rtext : initializing
… setting and getting data …
# add some data
quote$char_data_set("first", 1, TRUE)
quote$char_data_set("last", quote$char_length(), TRUE)
# get the data
quote$char_data_get()## i char first last
## 1 1 O TRUE NA
## 2 85 . NA TRUE
… text transformation and data update …
# transform text
quote$char_add("[this is an insertion] \n", 47)
# get the data again (see, the data moved along with the text)
quote$text_get()## [1] "Outside of a dog, a book is man's best friend. [this is an insertion] \nInside of a dog it's too dark to read."## i char first last
## 1 1 O TRUE NA
## 2 109 . NA TRUE
… using regular expression for setting data …
# do some convenience coding (via regular expressions)
quote$char_data_set_regex("dog_friend", "dog", "dog")
quote$char_data_set_regex("dog_friend", "friend", "friend")
quote$char_data_get()## i char first last dog_friend
## 1 1 O TRUE NA <NA>
## 2 14 d NA NA dog
## 3 15 o NA NA dog
## 4 16 g NA NA dog
## 5 40 f NA NA friend
## 6 41 r NA NA friend
## 7 42 i NA NA friend
## 8 43 e NA NA friend
## 9 44 n NA NA friend
## 10 45 d NA NA friend
## 11 84 d NA NA dog
## 12 85 o NA NA dog
## 13 86 g NA NA dog
## 14 109 . NA TRUE <NA>
… data aggregation via regex …
## token_i from to token is_token first last dog_friend
## 1 1 1 13 Outside of a TRUE TRUE NA <NA>
## 2 2 14 16 dog FALSE NA NA dog
## 3 3 17 39 , a book is man's best TRUE NA NA <NA>
## 4 4 40 45 friend FALSE NA NA friend
## 5 5 46 83 . [this is an insertion] \nInside of a TRUE NA NA <NA>
## 6 6 84 86 dog FALSE NA NA dog
## 7 7 87 109 it's too dark to read. TRUE NA TRUE <NA>
… data aggregation by words …
## token_i from to token is_token first last dog_friend
## 1 1 1 7 Outside TRUE TRUE NA <NA>
## 2 2 8 8 FALSE NA NA <NA>
## 3 3 9 10 of TRUE NA NA <NA>
## 4 4 11 11 FALSE NA NA <NA>
## 5 5 12 12 a TRUE NA NA <NA>
## 6 6 13 13 FALSE NA NA <NA>
## 7 7 14 16 dog TRUE NA NA dog
## 8 8 17 18 , FALSE NA NA <NA>
## 9 9 19 19 a TRUE NA NA <NA>
## 10 10 20 20 FALSE NA NA <NA>
## 11 11 21 24 book TRUE NA NA <NA>
## 12 12 25 25 FALSE NA NA <NA>
## 13 13 26 27 is TRUE NA NA <NA>
## 14 14 28 28 FALSE NA NA <NA>
## 15 15 29 31 man TRUE NA NA <NA>
## 16 16 32 32 ' FALSE NA NA <NA>
## 17 17 33 33 s TRUE NA NA <NA>
## 18 18 34 34 FALSE NA NA <NA>
## 19 19 35 38 best TRUE NA NA <NA>
## 20 20 39 39 FALSE NA NA <NA>
## 21 21 40 45 friend TRUE NA NA friend
## 22 22 46 48 . [ FALSE NA NA <NA>
## 23 23 49 52 this TRUE NA NA <NA>
## 24 24 53 53 FALSE NA NA <NA>
## 25 25 54 55 is TRUE NA NA <NA>
## 26 26 56 56 FALSE NA NA <NA>
## 27 27 57 58 an TRUE NA NA <NA>
## 28 28 59 59 FALSE NA NA <NA>
## 29 29 60 68 insertion TRUE NA NA <NA>
## 30 30 69 71 ] \n FALSE NA NA <NA>
## 31 31 72 77 Inside TRUE NA NA <NA>
## 32 32 78 78 FALSE NA NA <NA>
## 33 33 79 80 of TRUE NA NA <NA>
## 34 34 81 81 FALSE NA NA <NA>
## 35 35 82 82 a TRUE NA NA <NA>
## 36 36 83 83 FALSE NA NA <NA>
## 37 37 84 86 dog TRUE NA NA dog
## 38 38 87 87 FALSE NA NA <NA>
## 39 39 88 89 it TRUE NA NA <NA>
## 40 40 90 90 ' FALSE NA NA <NA>
## 41 41 91 91 s TRUE NA NA <NA>
## 42 42 92 92 FALSE NA NA <NA>
## 43 43 93 95 too TRUE NA NA <NA>
## 44 44 96 96 FALSE NA NA <NA>
## 45 45 97 100 dark TRUE NA NA <NA>
## 46 46 101 101 FALSE NA NA <NA>
## 47 47 102 103 to TRUE NA NA <NA>
## 48 48 104 104 FALSE NA NA <NA>
## 49 49 105 108 read TRUE NA NA <NA>
## 50 50 109 109 . FALSE NA TRUE <NA>
… data aggregation by lines …
## token_i from to token is_token first
## 1 1 1 70 Outside of a dog, a book is man's best friend. [this is an insertion] TRUE NA
## 2 2 72 109 Inside of a dog it's too dark to read. TRUE NA
## last dog_friend
## 1 NA friend
## 2 NA dog
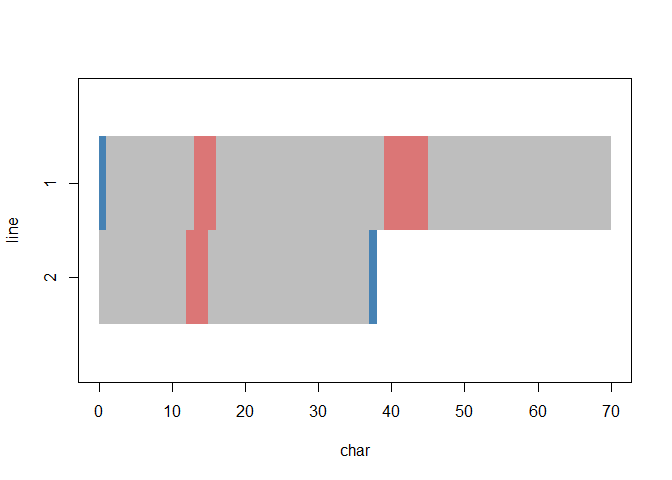
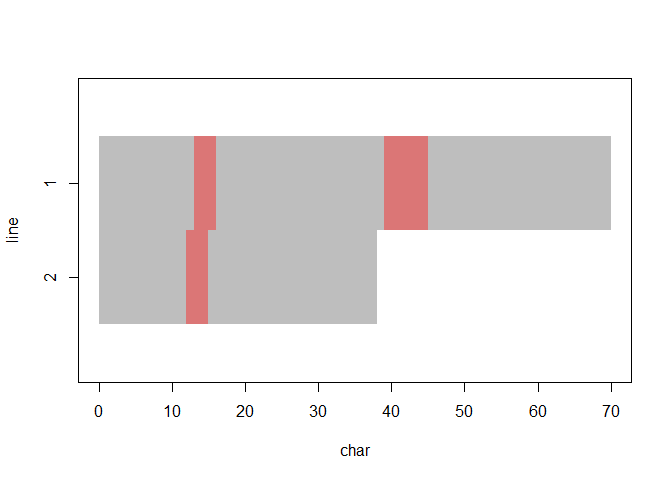
… text plotting with data highlighting …
… adding further data to the plot …
plot(quote, "dog_friend")
plot(quote, "first", col="steelblue", add=TRUE)
plot(quote, "last", col="steelblue", add=TRUE)