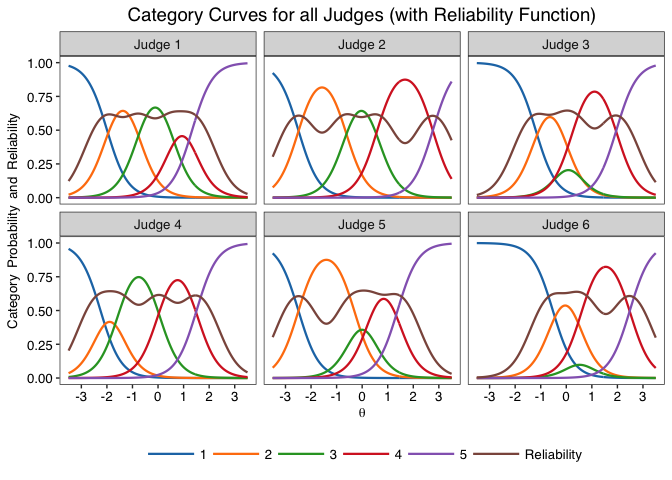
The goal of jrt is to provide tools to use Item-Response Theory (IRT) models on judgment data, especially in the context of the Consensual Assessment Technique, as presented in Myszkowski & Storme (2019).
You can install the released version of jrt from CRAN with:
fit <- jrt(data, progress.bar = F)
#> The possible responses detected are: 1-2-3-4-5
#>
#> -== Model Selection (6 judges) ==-
#> AICc for Rating Scale Model: 4414.924 | Model weight: 0.000
#> AICc for Generalized Rating Scale Model: 4370.699 | Model weight: 0.000
#> AICc for Partial Credit Model: 4027.701 | Model weight: 0.000
#> AICc for Generalized Partial Credit Model: 4021.567 | Model weight: 0.000
#> AICc for Constrained Graded Rating Scale Model: 4400.553 | Model weight: 0.000
#> AICc for Graded Rating Scale Model: 4310.307 | Model weight: 0.000
#> AICc for Constrained Graded Response Model: 4003.993 | Model weight: 0.859
#> AICc for Graded Response Model: 4007.604 | Model weight: 0.141
#> -> The best fitting model is the Constrained Graded Response Model.
#>
#> -== General Summary ==-
#> - 6 Judges
#> - 300 Products
#> - 5 response categories (1-2-3-4-5)
#> - Mean judgment = 2.977 | SD = 0.862
#>
#> -== IRT Summary ==-
#> - Model: Constrained (equal slopes) Graded Response Model (Samejima, 1969) | doi: 10.1007/BF03372160
#> - Estimation package: mirt (Chalmers, 2012) | doi: 10.18637/jss.v048.i06
#> - Estimation algorithm: Expectation-Maximization (EM; Bock & Atkin, 1981) | doi: 10.1007/BF02293801
#> - Method of factor scoring: Expected A Posteriori (EAP)
#> - AIC = 3999.249 | AICc = 4003.993 | BIC = 4091.843 | SABIC = 3999.249
#>
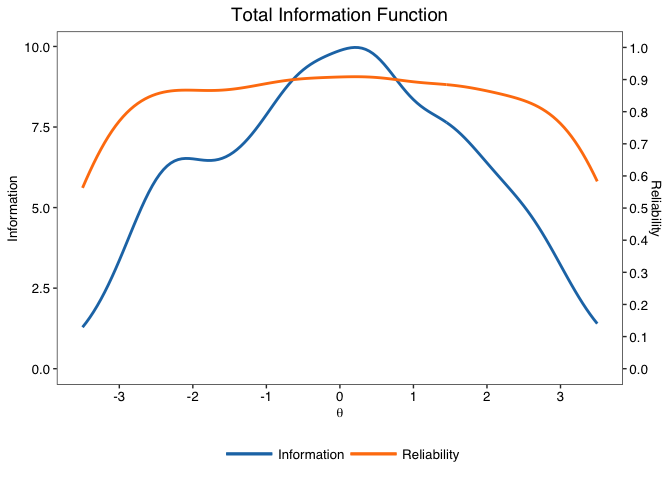
#> -== Model-based reliability ==-
#> - Empirical reliability | Average in the sample: .893
#> - Expected reliability | Assumes a Normal(0,1) prior density: .894
fit <- jrt(data, irt.model = "PCM")
#> The possible responses detected are: 1-2-3-4-5
#>
#> -== General Summary ==-
#> - 6 Judges
#> - 300 Products
#> - 5 response categories (1-2-3-4-5)
#> - Mean judgment = 2.977 | SD = 0.862
#>
#> -== IRT Summary ==-
#> - Model: Partial Credit Model (Masters, 1982) | doi: 10.1007/BF02296272
#> - Estimation package: mirt (Chalmers, 2012) | doi: 10.18637/jss.v048.i06
#> - Estimation algorithm: Expectation-Maximization (EM; Bock & Atkin, 1981) | doi: 10.1007/BF02293801
#> - Method of factor scoring: Expected A Posteriori (EAP)
#> - AIC = 4022.957 | AICc = 4027.701 | BIC = 4115.551 | SABIC = 4022.957
#>
#> -== Model-based reliability ==-
#> - Empirical reliability | Average in the sample: .889
#> - Expected reliability | Assumes a Normal(0,1) prior density: .759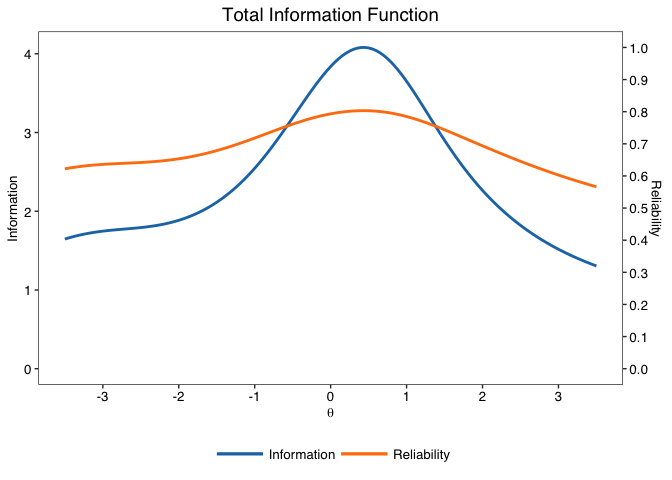
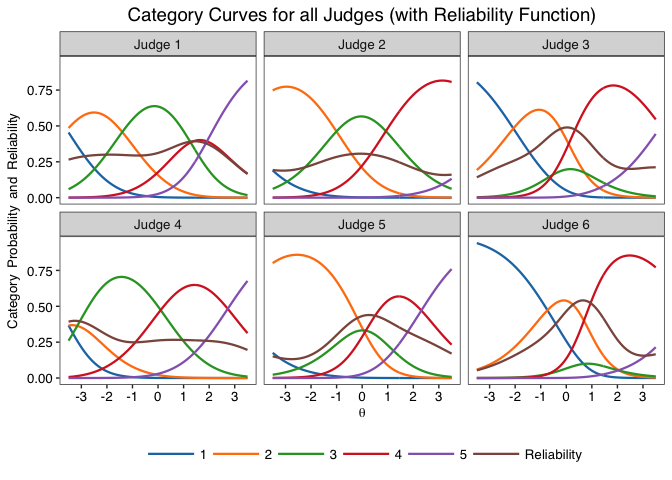
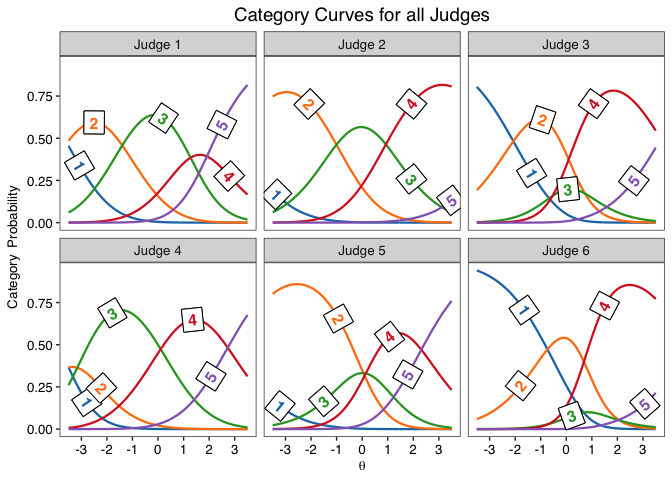
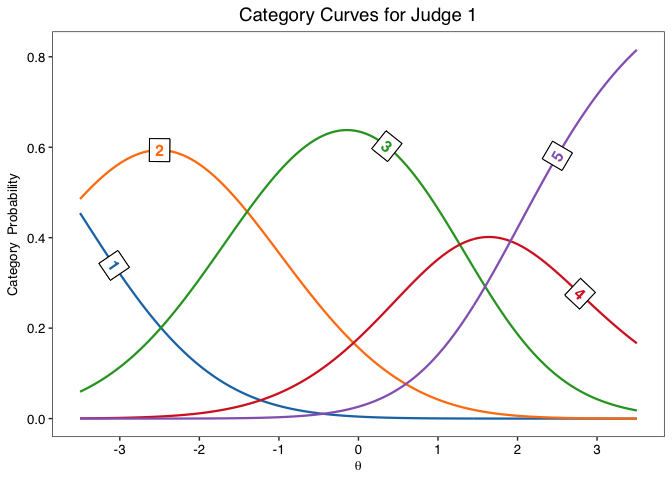
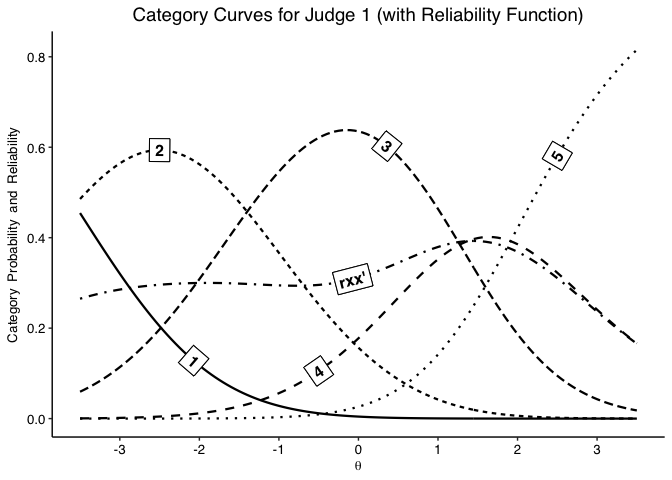
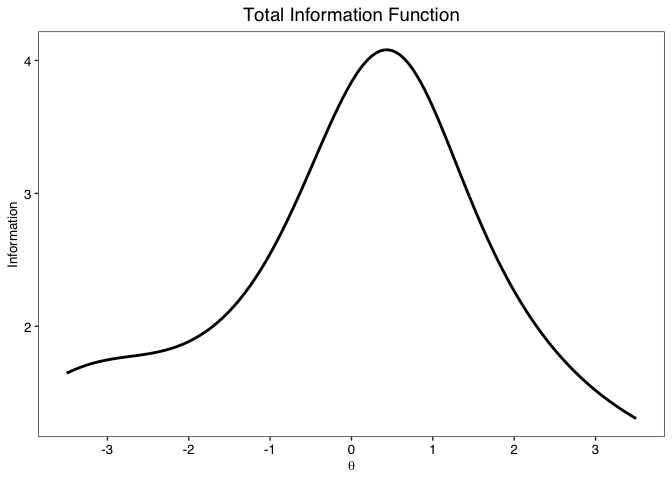
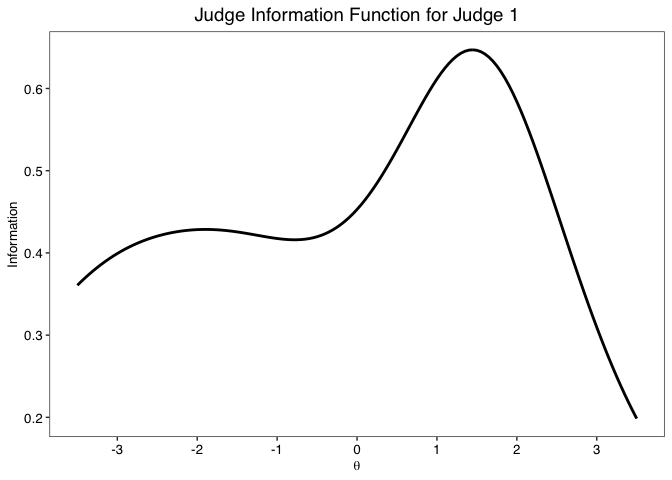
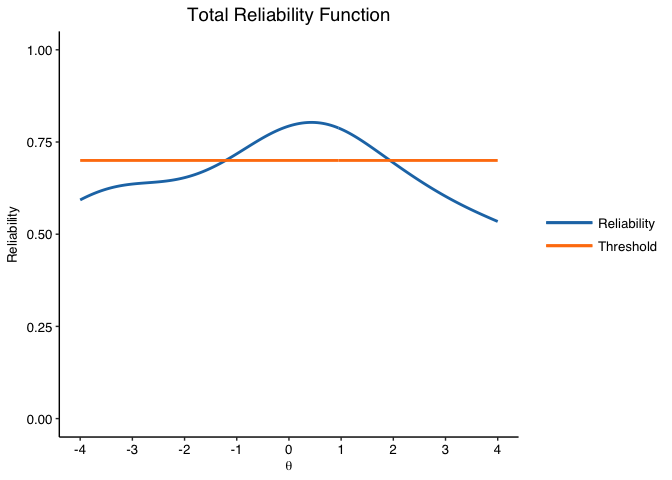
info.plot(fit, type = "Reliability",
y.line = .70,
y.limits = c(0,1),
theta.span = 4,
theme = "classic")