The goal of StratifiedMedicine is to develop analytic and visualization tools to aid in stratified and personalized medicine. Stratified medicine aims to find subsets or subgroups of patients with similar treatment effects, for example responders vs non-responders, while personalized medicine aims to understand treatment effects at the individual level (does a specific individual respond to treatment A?). Development of the package is ongoing.
Currently, the main tools in this package area: (1) Filter Models (identify important variables and reduce input covariate space), (2) Patient-Level Estimate Models (using regression models, estimate counterfactual quantities, such as the individual treatment effect), (3) Subgroup Models (identify groups of patients using tree-based approaches), and (4) Parameter Estimation (across the identified subgroups), and (5) PRISM (Patient Response Identifiers for Stratified Medicine; combines tools 1-4). Development of this package is ongoing.
Given a data-structure of (Y,A,X) (outcome, treatments, covariates), PRISM is a five step feature, which comprise of individual tools mentioned above:
Filter (filter_train): Reduce covariate space by removing variables unrelated to outcome/treatment.
Patient-level estimate (ple_train): Estimate counterfactual patient-level quantities, for example the individual treatment effect, ((x) = E(Y|X=x,A=1)-E(Y|X=x,A=0)).
Subgroup model (submod_train): Tree-based models to identify groups with hetergenous treatment effects (ex: responder vs non-responder)
Parameter estimation and inference (param_est): For the overall population and discovered subgroups, output point estimates and variability metrics. These outputs are crucial for Go-No-Go decision making.
Resampling: Steps 1-4 are repeated through bootstrap resampling for improved parameter estimation and inference.
You can install the released version of StratifiedMedicine from CRAN with:
And the development version from GitHub with:
Suppose the estimand or question of interest is the average treatment effect, (0 = E(Y|A=1)-E(Y|A=0)). The goal is to understand whether there is any treatment heterogeneity across patients and if there are any distinct subgroups with similar responses. In this example, we simulate continuous data where roughly 30% of the patients receive no treatment-benefit for using (A=1) vs (A=0). Responders vs non-responders are defined by the continuous predictive covariates (X_1) and (X_2) for a total of four subgroups. Subgroup treatment effects are: ({1} = 0) ((X_1 0, X_2 0)), ({2} = 0.25 (X_1 > 0, X_2 0)), ({3} = 0.45 (X_1 0, X2 > 0)), (_{4} = 0.65 (X_1>0, X_2>0)).
library(StratifiedMedicine)
## basic example code
dat_ctns = generate_subgrp_data(family="gaussian")
Y = dat_ctns$Y
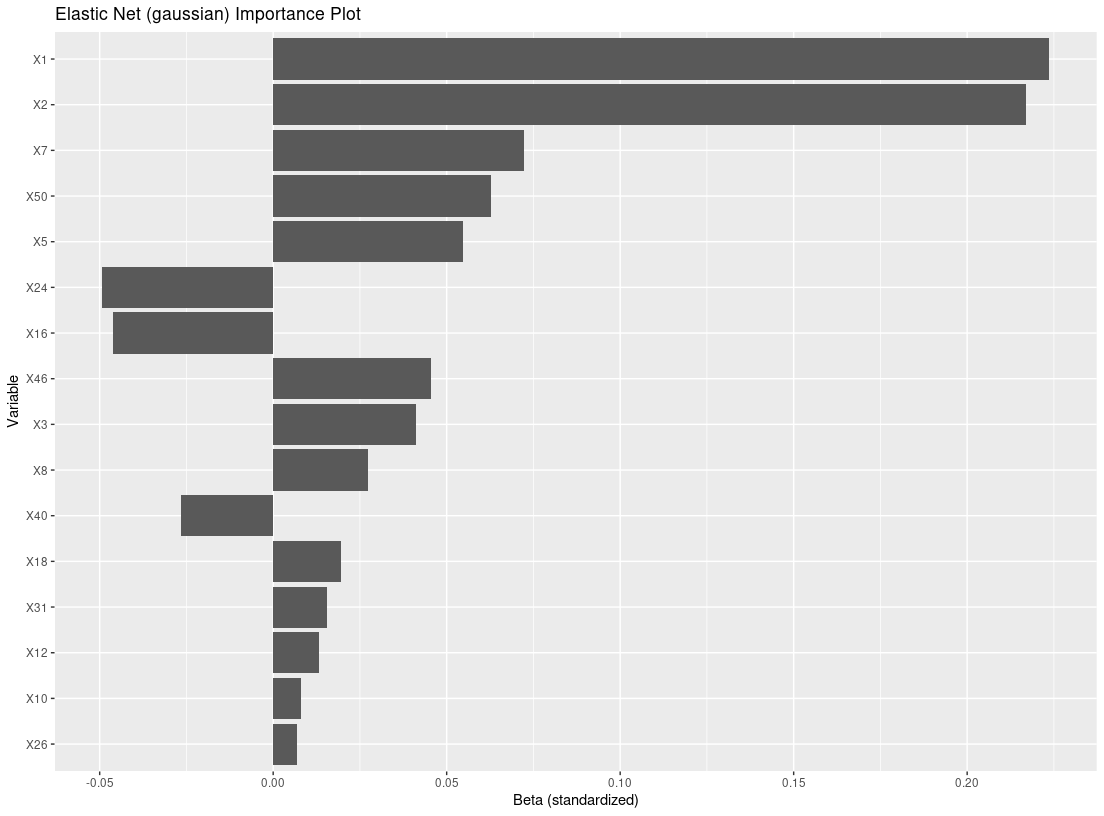
X = dat_ctns$X # 50 covariates, 46 are noise variables, X1 and X2 are truly predictive
A = dat_ctns$A # binary treatment, 1:1 randomized
# Filter #
res_f <- filter_train(Y, A, X, filter="glmnet")
plot_importance(res_f)
# counterfactual estimates (ple) #
res_p <- ple_train(Y, A, X, ple="ranger")
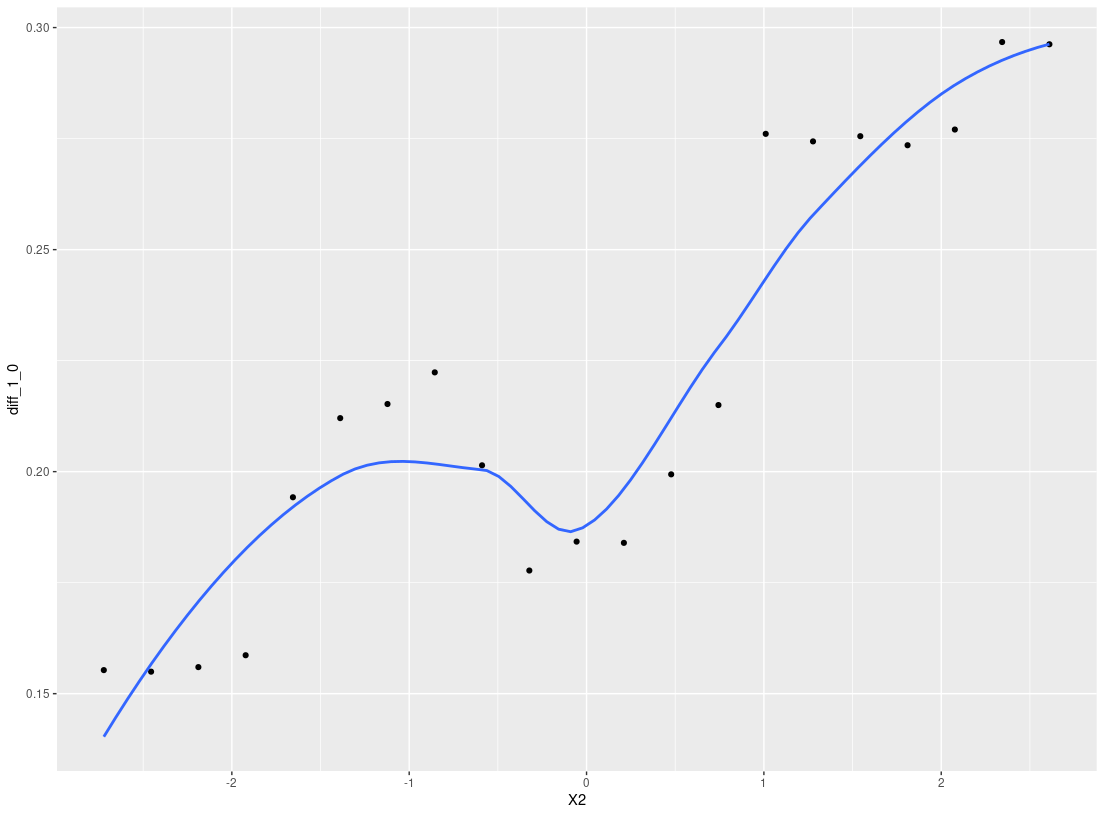
plot_dependence(res_p, X=X, vars="X1")
#> `geom_smooth()` using method = 'loess' and formula 'y ~ x'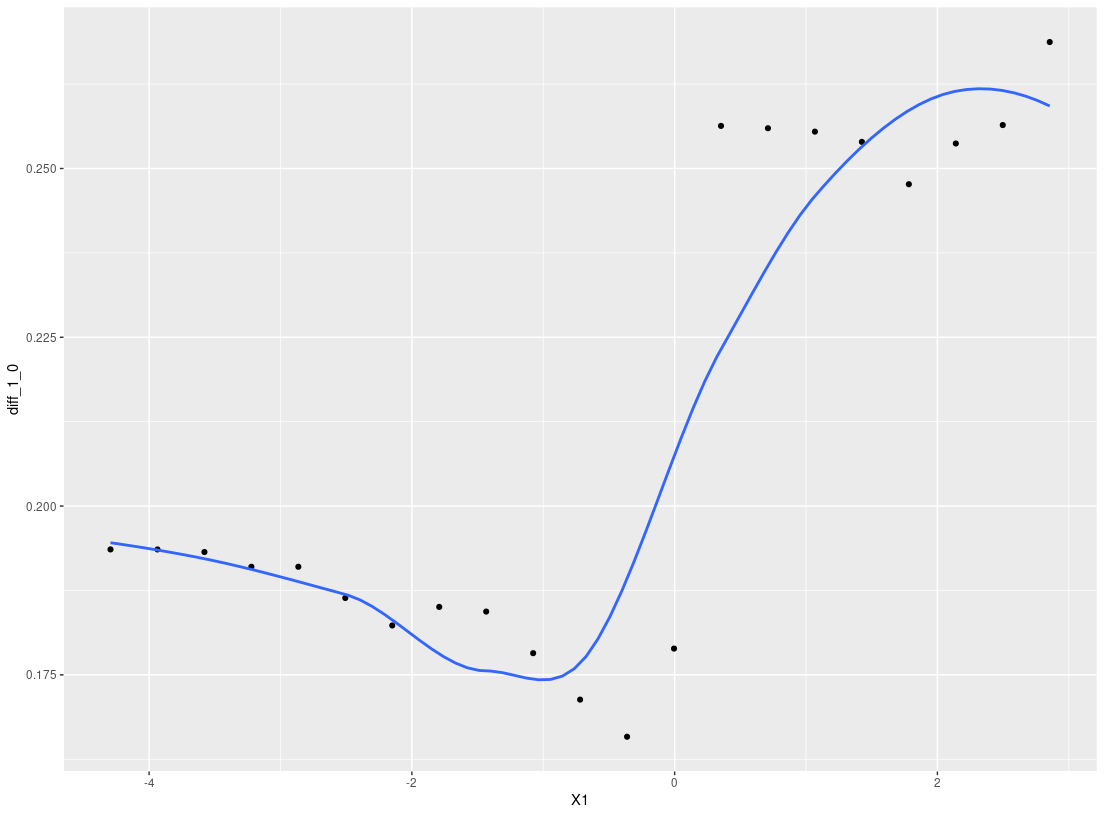
# PRISM Default: filter=glmnet, ple=ranger, submod=lmtree, param=dr #
res0 = PRISM(Y=Y, A=A, X=X)
#> Observed Data
#> Filtering: glmnet
#> PLE: ranger
#> Subgroup Identification: lmtree
#> Parameter Estimation: dr
plot(res0) # default: tree plot 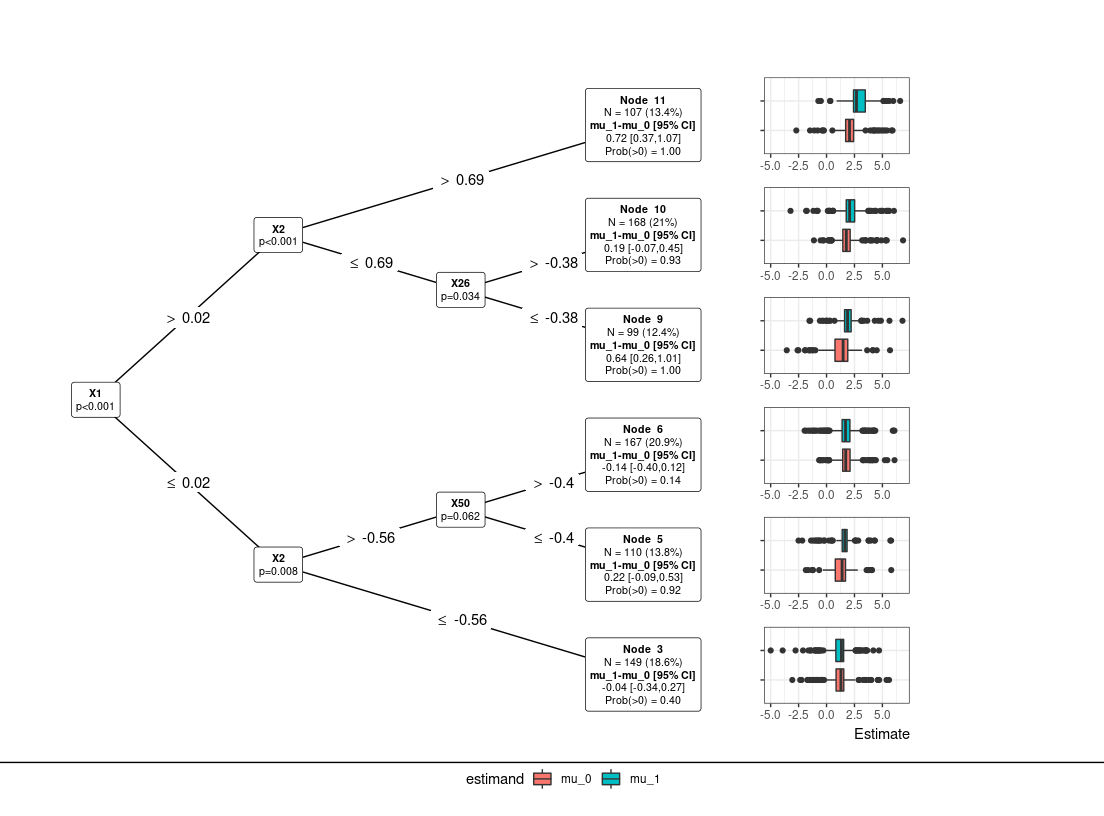
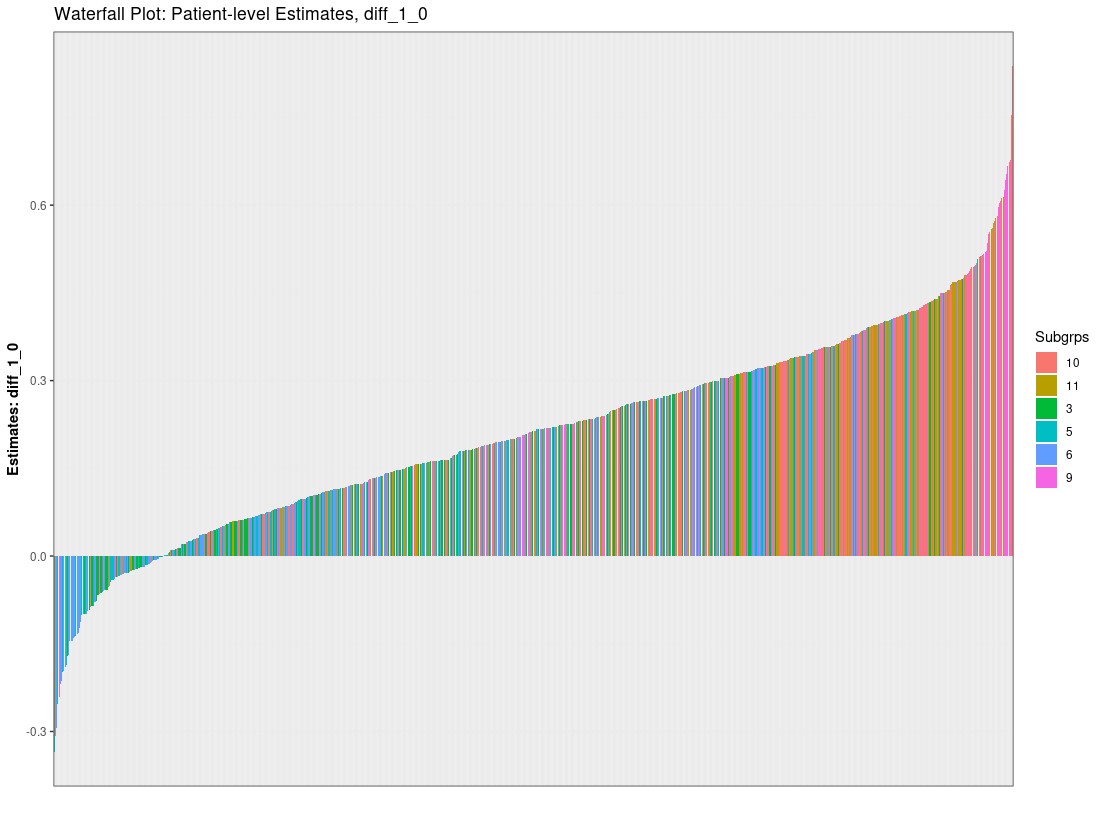
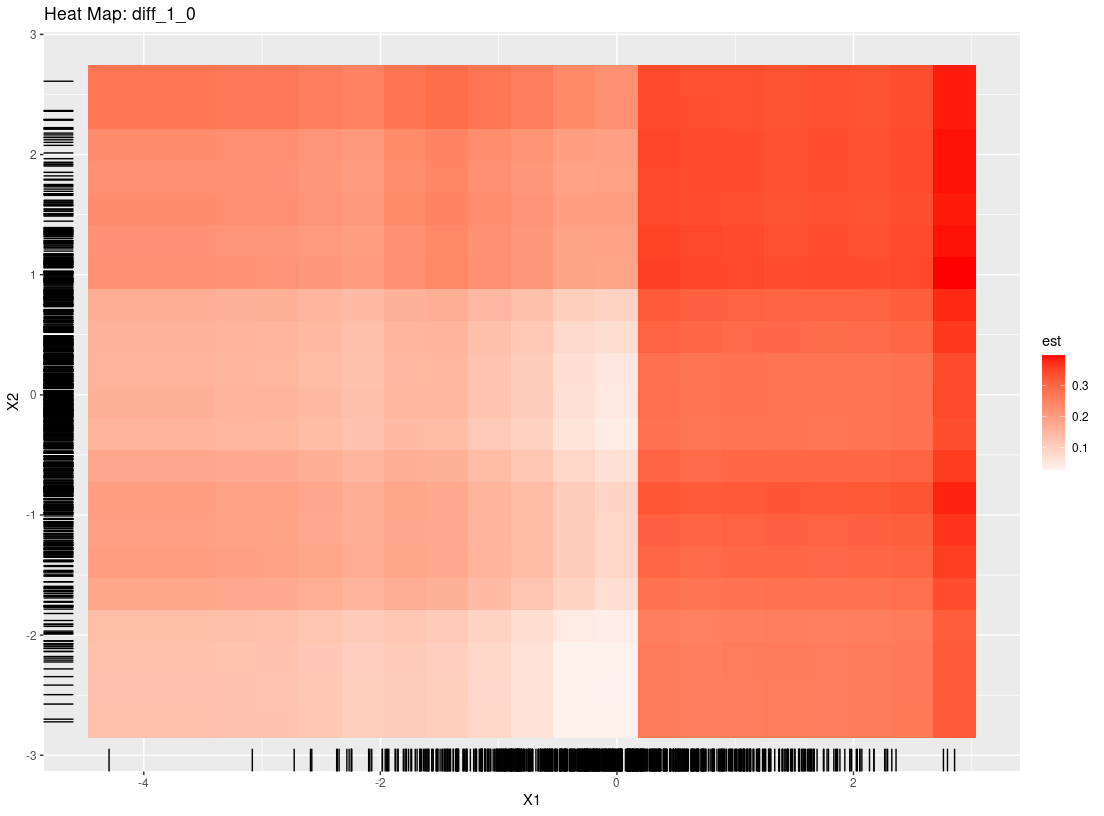
## Dependence Plots (univariate and heat maps)
plot_dependence(res0, vars="X1")
#> `geom_smooth()` using method = 'loess' and formula 'y ~ x'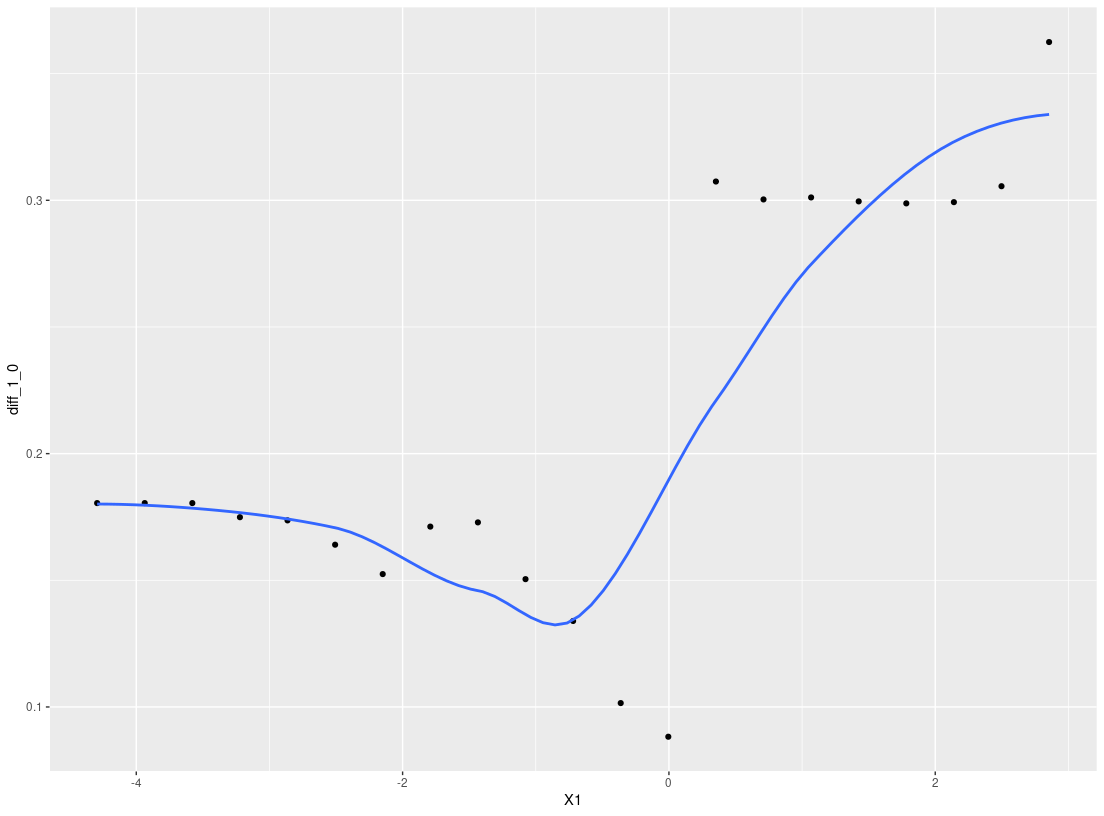
Overall, StratifiedMedicine provides information at the patient-level, the subgroup-level (if any), and the overall population. While there are defaults in place, the user can also input their own functions/model wrappers into each of the individual tools. For more details and more examples, we refer the reader to the following vignettes, SM_overview, User_Specific_Models.