

![]()
Bayesian learning is built on an assumption that the model space contains a true reflection of the data generating mechanism. This assumption is problematic, particularly in complex data environments. By using a Bayesian non-parametric approach to learning, we no longer have to assume that the model is true.
This package implements a non-parametric statistical model using a parallelised Monte Carlo sampling scheme. The method implemented in this package allows non-parameteric inference to be regularized for small sample sizes, while also being more accurate than approximations such as variational Bayes.
The concentration parameter is an effective sample size parameter, determining the faith we have in the model versus the data. When the concentration is low, the samples are close to the exact Bayesian logistic regression method; when the concentration is high, the samples are close to the simplified variational Bayes logistic regression.
You can install from Github with devtools:
requireNamespace("devtools", quietly = TRUE)
devtools::install_github("https://github.com/alan-turing-institute/PosteriorBootstrap/")Please see the provided vignette (at vignettes/PosteriorBootstrap.Rmd) for an example usage of the package to fit a logistic regression model to the Statlog German Credit dataset.
The vignette reproduces Figure 2, page 8, from Lyddon, Walker, and Holmes (2018), “Nonparametric learning from Bayesian models with randomized objective functions” (32nd Conference on Neural Information Processing Systems, Montréal, Canada). The vignette is limited to a concentration parameter of c = 500 and the figure below reproduces the one from the paper with the same concentration parameters.
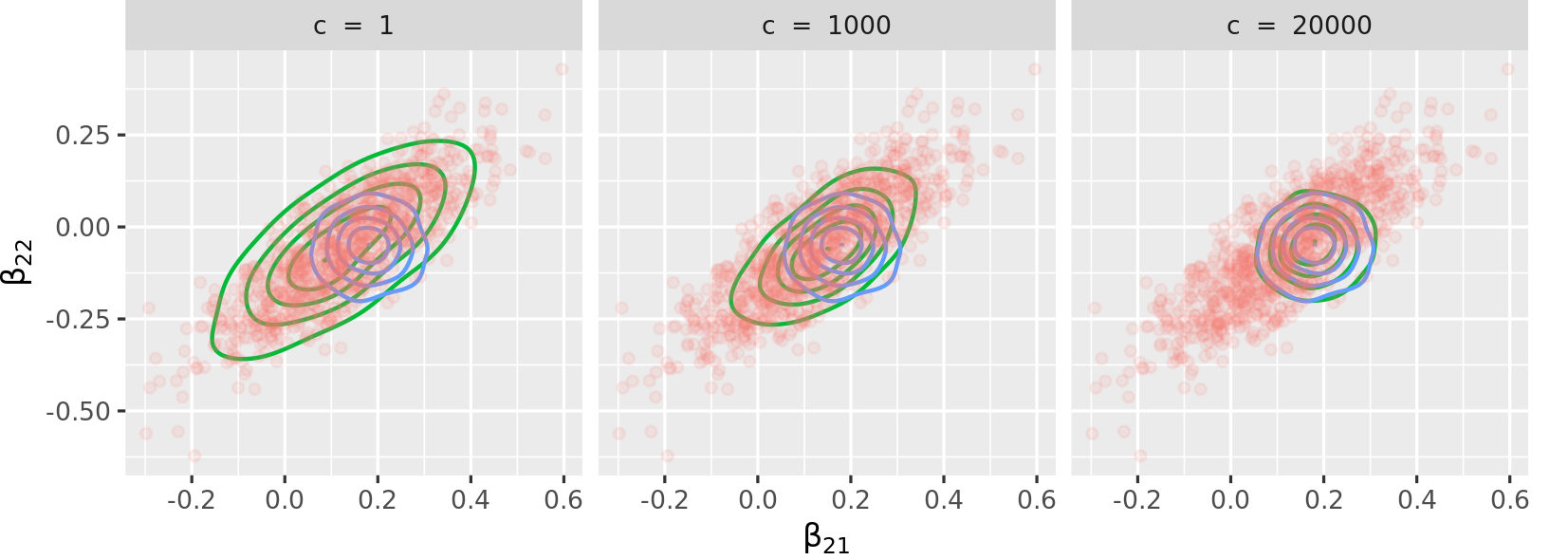
The figure above shows the advantage of the package: one can tune the proximity of the sampling method to exact inference (Bayesian logistic regression) with a low c or to approximate inference (variational inference) with high c, or anywhere in between. As mentioned in page 3 of the paper, the concentration parameter c is an effective sample size, governing the trust we have in the parametric model.
The user discussion and development of strace take place on Github issues.
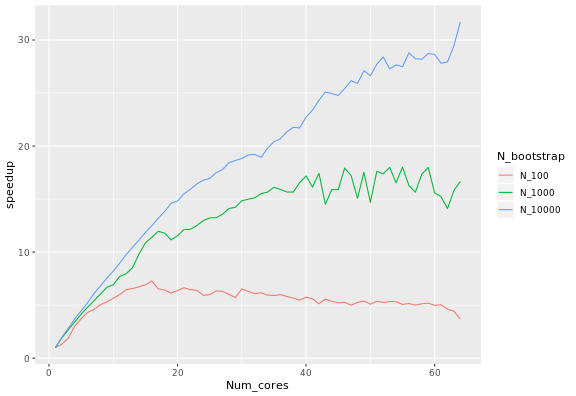
The calculation of the expected speedup depends on the number of bootstrap samples and the number of processors. It also depends on the system: it is larger on macOS than on Linux, with some variation depending on the version of R.
Fixing the number of samples corresponds to Ahmdal’s law, or the speedup in the task as a function of the number of processors. The speedup S_latency of N processors is defined as the duration of the task with one core divided by the duration of the task with N processors. For the number of bootstrap samples in 100, 1000, and 10,000, the speedup is:
Inverting Ahmdal’s law gives the proportion of the execution time that is parallelisable from the speedup
\[ p = \frac{\frac{1}{S_{latency}}} - 1}{\frac{1}{s} - 1} \]
where \(S_{latency}\) is the theoretical speedup of the whole task in Ahmdal’s law and the observed speedup here, and \(s\) is the speedup of the part of the task that can be parallelised, and thus equal to the number of processors. Calculating this value for the durations from 1 to 64 cores gives this plot:
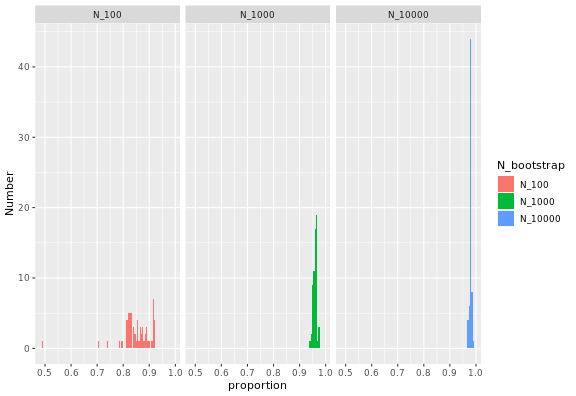
The proportion of the code that can be parallelised is high, and higher the large the bootstrap samples, and always below 1. For large samples with n_bootstrap = 10,000, the values are close to 100%.
To run the results in this section automatically, you’ll need a Microsoft Azure subscription (one of the free subscriptions for example) and the Azure Command-Line Interface (CLI). You will need to login to your Azure account with the Azure CLI:
then follow the instructions. You will need to create a resource group on portal.azure.com and make note of the name of the resource group. The default name of the resource group is PB for PosteriorBootstrap.
Then run the following on a shell with current directory at the root of the repository for deploying on a new machine:
or, to deploy on an existing machine:
The path to your private key defaults to ~/.ssh/azure if you do not specify it, and the public key is that path with the suffix .pub.
If you need to generate a private-public key pair, run: