
![]()
Often the first problem in understanding the generalized linear model in a practical way is finding good data. Common problems include finding data with a small number of rows, the response variable does not follow a family in the glm framework, or the data is messy and needs a lot of work before statistical analysis can begin. This package alleviates all of these by allowing you to create the data you want. With data in hand, you can empirically answer any question you have.
The goal of this package is to strike a balance between mathematical flexibility and simplicity of use. You can control the sample size, link function, number of unrelated variables, and ancillary parameter when applicable. Default values are carefully chosen so data can be generated without thinking about mathematical connections between weights, links, and distributions.
You can install the released version of GlmSimulatoR from CRAN with:
And the development version from GitHub with:
library(GlmSimulatoR)
library(ggplot2)
set.seed(1)
simdata <- simulate_gaussian(N = 100, weights = 1, xrange = 10, ancillary = 1) #GlmSimulatoR function
ggplot(simdata, aes(x = X1, y = Y)) +
geom_point()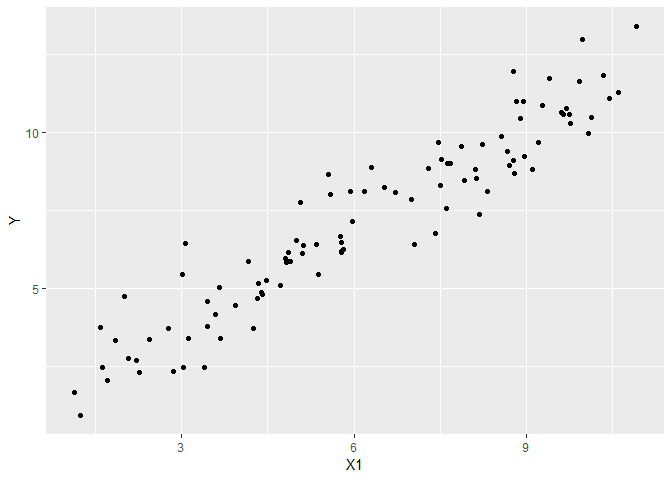
library(GlmSimulatoR)
set.seed(2)
simdata <- simulate_gaussian() #GlmSimulatoR function
linearModel <- lm(Y ~ X1 + X2 + X3, data = simdata)
glmModel <- glm(Y ~ X1 + X2 + X3, data = simdata, family = gaussian(link = "identity"))
summary(linearModel)$coefficients
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 2.9121432 0.09159228 31.79464 2.042126e-211
#> X1 0.9821122 0.03471228 28.29294 1.784922e-169
#> X2 2.0393412 0.03456867 58.99392 0.000000e+00
#> X3 3.0431138 0.03487595 87.25536 0.000000e+00
summary(glmModel)$coefficients
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 2.9121432 0.09159228 31.79464 2.042126e-211
#> X1 0.9821122 0.03471228 28.29294 1.784922e-169
#> X2 2.0393412 0.03456867 58.99392 0.000000e+00
#> X3 3.0431138 0.03487595 87.25536 0.000000e+00
rm(linearModel, glmModel, simdata)In the summary, the weights and standard errors are the same.